 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimary Care Diagnoses as a Reliable Predictor for Orthopedic Surgical Interventions
Feb 06, 2025Referral workflow inefficiencies, including misaligned referrals and delays, contribute to suboptimal patient outcomes and higher healthcare costs. In this study, we investigated the possibility of predicting procedural needs based on primary care diagnostic entries, thereby improving referral accuracy, streamlining workflows, and providing better care to patients. A de-identified dataset of 2,086 orthopedic referrals from the University of Texas Health at Tyler was analyzed using machine learning models built on Base General Embeddings (BGE) for semantic extraction. To ensure real-world applicability, noise tolerance experiments were conducted, and oversampling techniques were employed to mitigate class imbalance. The selected optimum and parsimonious embedding model demonstrated high predictive accuracy (ROC-AUC: 0.874, Matthews Correlation Coefficient (MCC): 0.540), effectively distinguishing patients requiring surgical intervention. Dimensionality reduction techniques confirmed the model's ability to capture meaningful clinical relationships. A threshold sensitivity analysis identified an optimal decision threshold (0.30) to balance precision and recall, maximizing referral efficiency. In the predictive modeling analysis, the procedure rate increased from 11.27% to an optimal 60.1%, representing a 433% improvement with significant implications for operational efficiency and healthcare revenue. The results of our study demonstrate that referral optimization can enhance primary and surgical care integration. Through this approach, precise and timely predictions of procedural requirements can be made, thereby minimizing delays, improving surgical planning, and reducing administrative burdens. In addition, the findings highlight the potential of clinical decision support as a scalable solution for improving patient outcomes and the efficiency of the healthcare system.
Utilization of Impedance Disparity Incurred from Switching Activities to Monitor and Characterize Firmware Activities
Jan 17, 2023The massive trend toward embedded systems introduces new security threats to prevent. Malicious firmware makes it easier to launch cyberattacks against embedded systems. Systems infected with malicious firmware maintain the appearance of normal firmware operation but execute undesirable activities, which is usually a security risk. Traditionally, cybercriminals use malicious firmware to develop possible back-doors for future attacks. Due to the restricted resources of embedded systems, it is difficult to thwart these attacks using the majority of contemporary standard security protocols. In addition, monitoring the firmware operations using existing side channels from outside the processing unit, such as electromagnetic radiation, necessitates a complicated hardware configuration and in-depth technical understanding. In this paper, we propose a physical side channel that is formed by detecting the overall impedance changes induced by the firmware actions of a central processing unit. To demonstrate how this side channel can be exploited for detecting firmware activities, we experimentally validate it using impedance measurements to distinguish between distinct firmware operations with an accuracy of greater than 90%. These findings are the product of classifiers that are trained via machine learning. The implementation of our proposed methodology also leaves room for the use of hardware authentication.
Determining Health Utilities through Data Mining of Social Media
Aug 13, 2016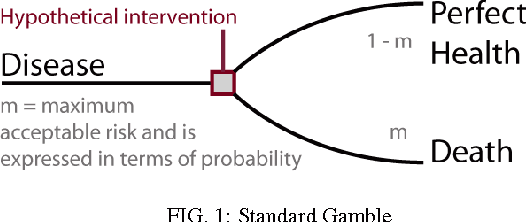
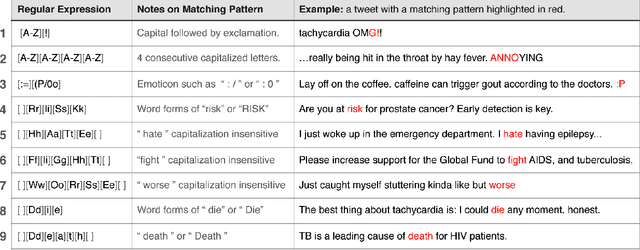


'Health utilities' measure patient preferences for perfect health compared to specific unhealthy states, such as asthma, a fractured hip, or colon cancer. When integrated over time, these estimations are called quality adjusted life years (QALYs). Until now, characterizing health utilities (HUs) required detailed patient interviews or written surveys. While reliable and specific, this data remained costly due to efforts to locate, enlist and coordinate participants. Thus the scope, context and temporality of diseases examined has remained limited. Now that more than a billion people use social media, we propose a novel strategy: use natural language processing to analyze public online conversations for signals of the severity of medical conditions and correlate these to known HUs using machine learning. In this work, we filter a dataset that originally contained 2 billion tweets for relevant content on 60 diseases. Using this data, our algorithm successfully distinguished mild from severe diseases, which had previously been categorized only by traditional techniques. This represents progress towards two related applications: first, predicting HUs where such information is nonexistent; and second, (where rich HU data already exists) estimating temporal or geographic patterns of disease severity through data mining.