 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetermining Health Utilities through Data Mining of Social Media
Paper and Code
Aug 13, 2016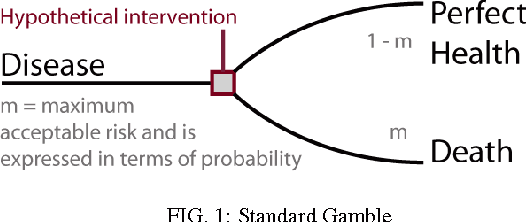
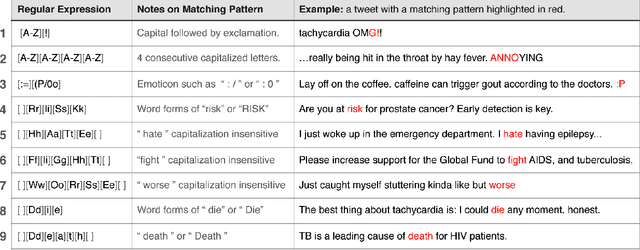


'Health utilities' measure patient preferences for perfect health compared to specific unhealthy states, such as asthma, a fractured hip, or colon cancer. When integrated over time, these estimations are called quality adjusted life years (QALYs). Until now, characterizing health utilities (HUs) required detailed patient interviews or written surveys. While reliable and specific, this data remained costly due to efforts to locate, enlist and coordinate participants. Thus the scope, context and temporality of diseases examined has remained limited. Now that more than a billion people use social media, we propose a novel strategy: use natural language processing to analyze public online conversations for signals of the severity of medical conditions and correlate these to known HUs using machine learning. In this work, we filter a dataset that originally contained 2 billion tweets for relevant content on 60 diseases. Using this data, our algorithm successfully distinguished mild from severe diseases, which had previously been categorized only by traditional techniques. This represents progress towards two related applications: first, predicting HUs where such information is nonexistent; and second, (where rich HU data already exists) estimating temporal or geographic patterns of disease severity through data mining.