 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Graph Generators
Sep 29, 2023


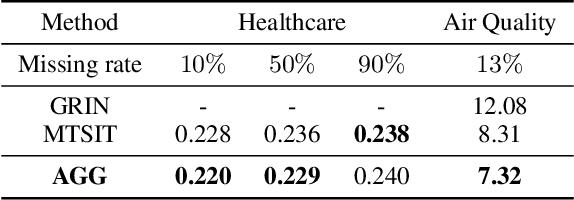
We introduce the asynchronous graph generator (AGG), a novel graph neural network architecture for multi-channel time series which models observations as nodes on a dynamic graph and can thus perform data imputation by transductive node generation. Completely free from recurrent components or assumptions about temporal regularity, AGG represents measurements, timestamps and metadata directly in the nodes via learnable embeddings, to then leverage attention to learn expressive relationships across the variables of interest. This way, the proposed architecture implicitly learns a causal graph representation of sensor measurements which can be conditioned on unseen timestamps and metadata to predict new measurements by an expansion of the learnt graph. The proposed AGG is compared both conceptually and empirically to previous work, and the impact of data augmentation on the performance of AGG is also briefly discussed. Our experiments reveal that AGG achieved state-of-the-art results in time series data imputation, classification and prediction for the benchmark datasets Beijing Air Quality, PhysioNet Challenge 2012 and UCI localisation.
Lossy Compression for Robust Unsupervised Time-Series Anomaly Detection
Dec 05, 2022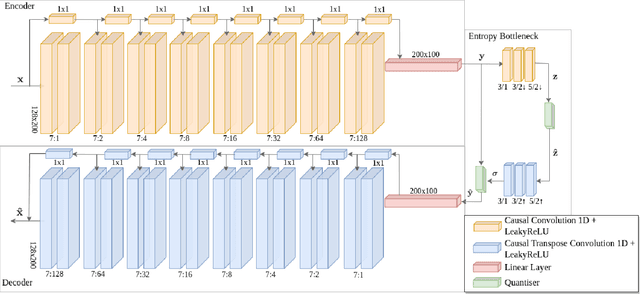
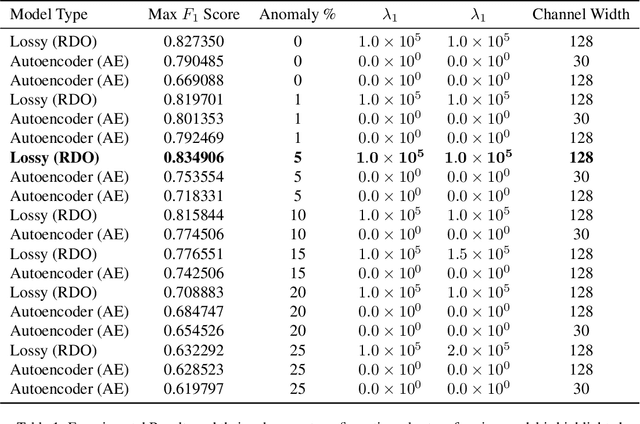
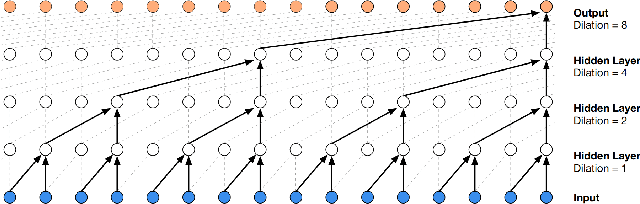
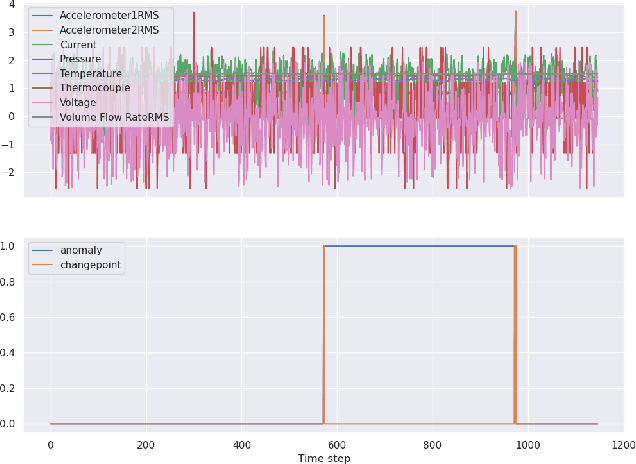
A new Lossy Causal Temporal Convolutional Neural Network Autoencoder for anomaly detection is proposed in this work. Our framework uses a rate-distortion loss and an entropy bottleneck to learn a compressed latent representation for the task. The main idea of using a rate-distortion loss is to introduce representation flexibility that ignores or becomes robust to unlikely events with distinctive patterns, such as anomalies. These anomalies manifest as unique distortion features that can be accurately detected in testing conditions. This new architecture allows us to train a fully unsupervised model that has high accuracy in detecting anomalies from a distortion score despite being trained with some portion of unlabelled anomalous data. This setting is in stark contrast to many of the state-of-the-art unsupervised methodologies that require the model to be only trained on "normal data". We argue that this partially violates the concept of unsupervised training for anomaly detection as the model uses an informed decision that selects what is normal from abnormal for training. Additionally, there is evidence to suggest it also effects the models ability at generalisation. We demonstrate that models that succeed in the paradigm where they are only trained on normal data fail to be robust when anomalous data is injected into the training. In contrast, our compression-based approach converges to a robust representation that tolerates some anomalous distortion. The robust representation achieved by a model using a rate-distortion loss can be used in a more realistic unsupervised anomaly detection scheme.