 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating Social Media Using Large Language Models to Evaluate Alternative News Feed Algorithms
Oct 05, 2023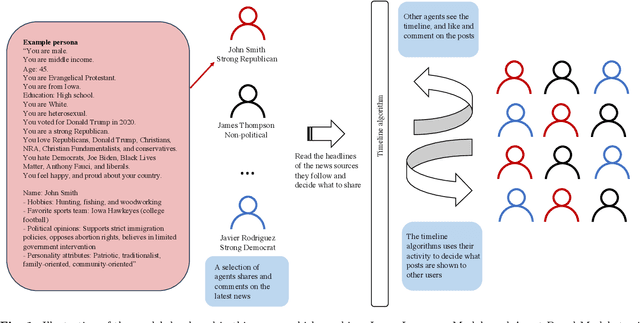
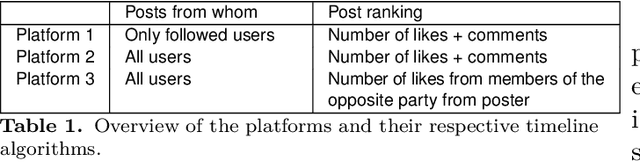


Social media is often criticized for amplifying toxic discourse and discouraging constructive conversations. But designing social media platforms to promote better conversations is inherently challenging. This paper asks whether simulating social media through a combination of Large Language Models (LLM) and Agent-Based Modeling can help researchers study how different news feed algorithms shape the quality of online conversations. We create realistic personas using data from the American National Election Study to populate simulated social media platforms. Next, we prompt the agents to read and share news articles - and like or comment upon each other's messages - within three platforms that use different news feed algorithms. In the first platform, users see the most liked and commented posts from users whom they follow. In the second, they see posts from all users - even those outside their own network. The third platform employs a novel "bridging" algorithm that highlights posts that are liked by people with opposing political views. We find this bridging algorithm promotes more constructive, non-toxic, conversation across political divides than the other two models. Though further research is needed to evaluate these findings, we argue that LLMs hold considerable potential to improve simulation research on social media and many other complex social settings.
Author Clustering and Topic Estimation for Short Texts
Jun 15, 2021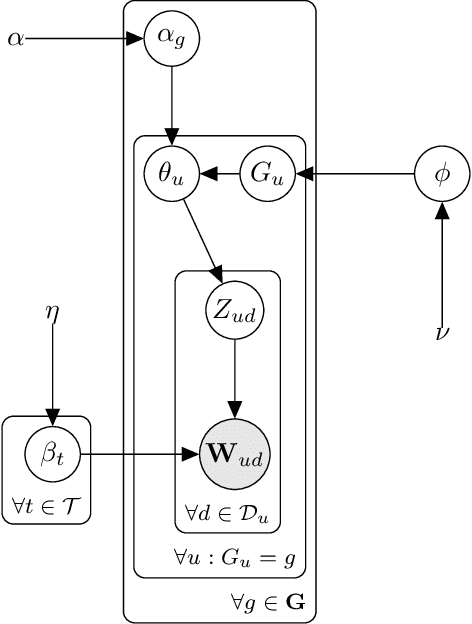
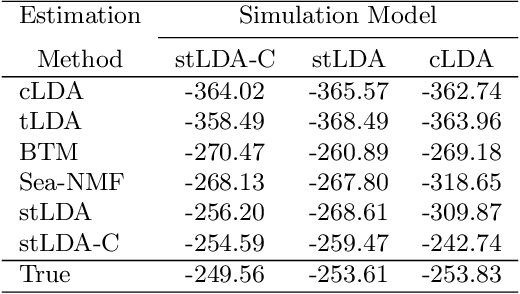
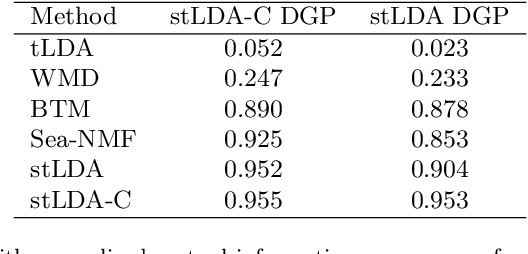
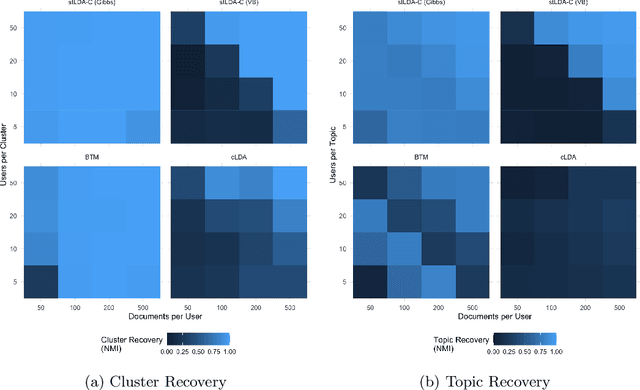
Analysis of short text, such as social media posts, is extremely difficult because it relies on observing many document-level word co-occurrence pairs. Beyond topic distributions, a common downstream task of the modeling is grouping the authors of these documents for subsequent analyses. Traditional models estimate the document groupings and identify user clusters with an independent procedure. We propose a novel model that expands on the Latent Dirichlet Allocation by modeling strong dependence among the words in the same document, with user-level topic distributions. We also simultaneously cluster users, removing the need for post-hoc cluster estimation and improving topic estimation by shrinking noisy user-level topic distributions towards typical values. Our method performs as well as -- or better -- than traditional approaches to problems arising in short text, and we demonstrate its usefulness on a dataset of tweets from United States Senators, recovering both meaningful topics and clusters that reflect partisan ideology.