 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Reproduce Racial Stereotypes When Used for Text Annotation
Mar 14, 2026Large language models (LLMs) are increasingly used for automated text annotation in tasks ranging from academic research to content moderation and hiring. Across 19 LLMs and two experiments totaling more than 4 million annotation judgments, we show that subtle identity cues embedded in text systematically bias annotation outcomes in ways that mirror racial stereotypes. In a names-based experiment spanning 39 annotation tasks, texts containing names associated with Black individuals are rated as more aggressive by 18 of 19 models and more gossipy by 18 of 19. Asian names produce a bamboo-ceiling profile: 17 of 19 models rate individuals as more intelligent, while 18 of 19 rate them as less confident and less sociable. Arab names elicit cognitive elevation alongside interpersonal devaluation, and all four minority groups are consistently rated as less self-disciplined. In a matched dialect experiment, the same sentence is judged significantly less professional (all 19 models, mean gap $-0.774$), less indicative of an educated speaker ($-0.688$), more toxic (18/19), and more angry (19/19) when written in African American Vernacular English rather than Standard American English. A notable exception occurs for name-based hireability, where fine-tuning appears to overcorrect, systematically favoring minority-named applicants. These findings suggest that using LLMs as automated annotators can embed socially patterned biases directly into the datasets and measurements that increasingly underpin research, governance, and decision-making.
Computational Turing Test Reveals Systematic Differences Between Human and AI Language
Nov 06, 2025Large language models (LLMs) are increasingly used in the social sciences to simulate human behavior, based on the assumption that they can generate realistic, human-like text. Yet this assumption remains largely untested. Existing validation efforts rely heavily on human-judgment-based evaluations -- testing whether humans can distinguish AI from human output -- despite evidence that such judgments are blunt and unreliable. As a result, the field lacks robust tools for assessing the realism of LLM-generated text or for calibrating models to real-world data. This paper makes two contributions. First, we introduce a computational Turing test: a validation framework that integrates aggregate metrics (BERT-based detectability and semantic similarity) with interpretable linguistic features (stylistic markers and topical patterns) to assess how closely LLMs approximate human language within a given dataset. Second, we systematically compare nine open-weight LLMs across five calibration strategies -- including fine-tuning, stylistic prompting, and context retrieval -- benchmarking their ability to reproduce user interactions on X (formerly Twitter), Bluesky, and Reddit. Our findings challenge core assumptions in the literature. Even after calibration, LLM outputs remain clearly distinguishable from human text, particularly in affective tone and emotional expression. Instruction-tuned models underperform their base counterparts, and scaling up model size does not enhance human-likeness. Crucially, we identify a trade-off: optimizing for human-likeness often comes at the cost of semantic fidelity, and vice versa. These results provide a much-needed scalable framework for validation and calibration in LLM simulations -- and offer a cautionary note about their current limitations in capturing human communication.
Who Attacks, and Why? Using LLMs to Identify Negative Campaigning in 18M Tweets across 19 Countries
Jul 23, 2025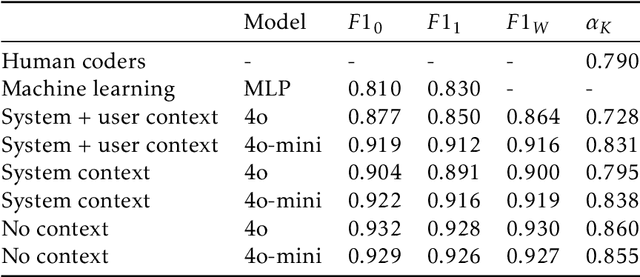
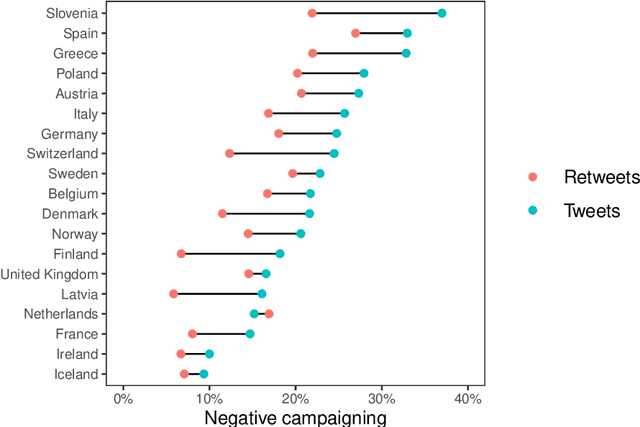
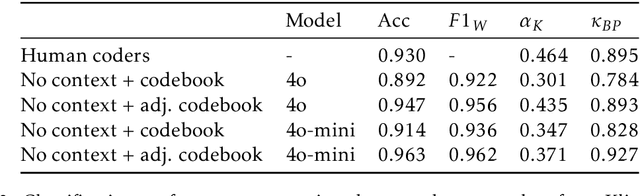
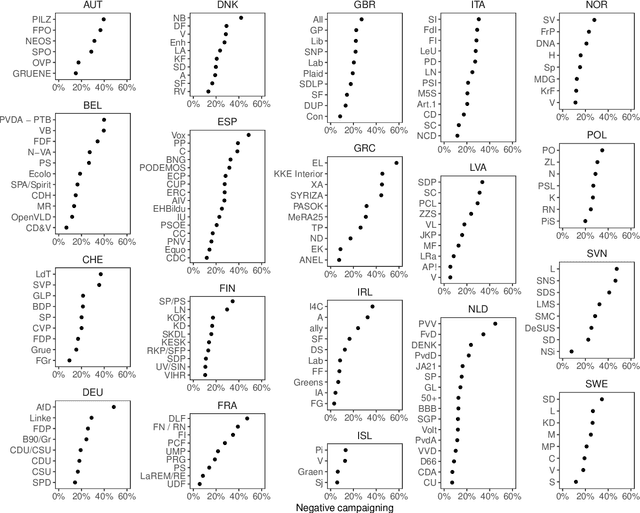
Negative campaigning is a central feature of political competition, yet empirical research has been limited by the high cost and limited scalability of existing classification methods. This study makes two key contributions. First, it introduces zero-shot Large Language Models (LLMs) as a novel approach for cross-lingual classification of negative campaigning. Using benchmark datasets in ten languages, we demonstrate that LLMs achieve performance on par with native-speaking human coders and outperform conventional supervised machine learning approaches. Second, we leverage this novel method to conduct the largest cross-national study of negative campaigning to date, analyzing 18 million tweets posted by parliamentarians in 19 European countries between 2017 and 2022. The results reveal consistent cross-national patterns: governing parties are less likely to use negative messaging, while ideologically extreme and populist parties -- particularly those on the radical right -- engage in significantly higher levels of negativity. These findings advance our understanding of how party-level characteristics shape strategic communication in multiparty systems. More broadly, the study demonstrates the potential of LLMs to enable scalable, transparent, and replicable research in political communication across linguistic and cultural contexts.
Emergent LLM behaviors are observationally equivalent to data leakage
May 26, 2025Ashery et al. recently argue that large language models (LLMs), when paired to play a classic "naming game," spontaneously develop linguistic conventions reminiscent of human social norms. Here, we show that their results are better explained by data leakage: the models simply reproduce conventions they already encountered during pre-training. Despite the authors' mitigation measures, we provide multiple analyses demonstrating that the LLMs recognize the structure of the coordination game and recall its outcomes, rather than exhibit "emergent" conventions. Consequently, the observed behaviors are indistinguishable from memorization of the training corpus. We conclude by pointing to potential alternative strategies and reflecting more generally on the place of LLMs for social science models.
Do Large Language Models Solve the Problems of Agent-Based Modeling? A Critical Review of Generative Social Simulations
Apr 04, 2025Recent advancements in AI have reinvigorated Agent-Based Models (ABMs), as the integration of Large Language Models (LLMs) has led to the emergence of ``generative ABMs'' as a novel approach to simulating social systems. While ABMs offer means to bridge micro-level interactions with macro-level patterns, they have long faced criticisms from social scientists, pointing to e.g., lack of realism, computational complexity, and challenges of calibrating and validating against empirical data. This paper reviews the generative ABM literature to assess how this new approach adequately addresses these long-standing criticisms. Our findings show that studies show limited awareness of historical debates. Validation remains poorly addressed, with many studies relying solely on subjective assessments of model `believability', and even the most rigorous validation failing to adequately evidence operational validity. We argue that there are reasons to believe that LLMs will exacerbate rather than resolve the long-standing challenges of ABMs. The black-box nature of LLMs moreover limit their usefulness for disentangling complex emergent causal mechanisms. While generative ABMs are still in a stage of early experimentation, these findings question of whether and how the field can transition to the type of rigorous modeling needed to contribute to social scientific theory.
Elite Political Discourse has Become More Toxic in Western Countries
Mar 28, 2025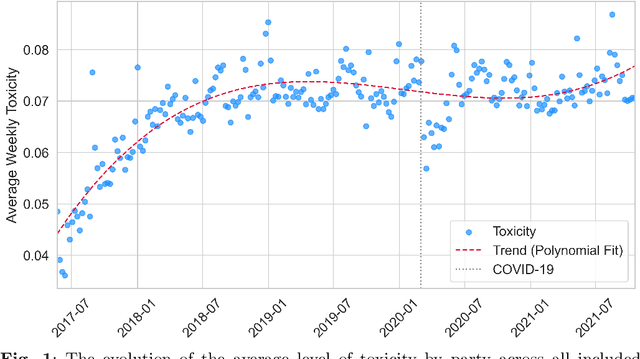
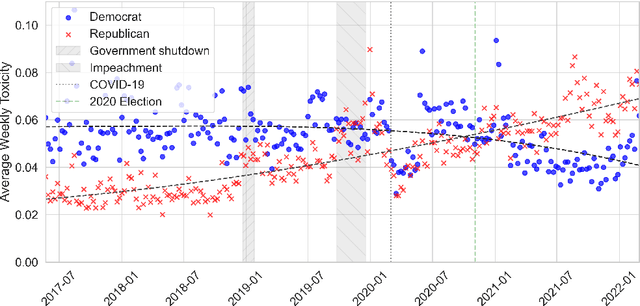
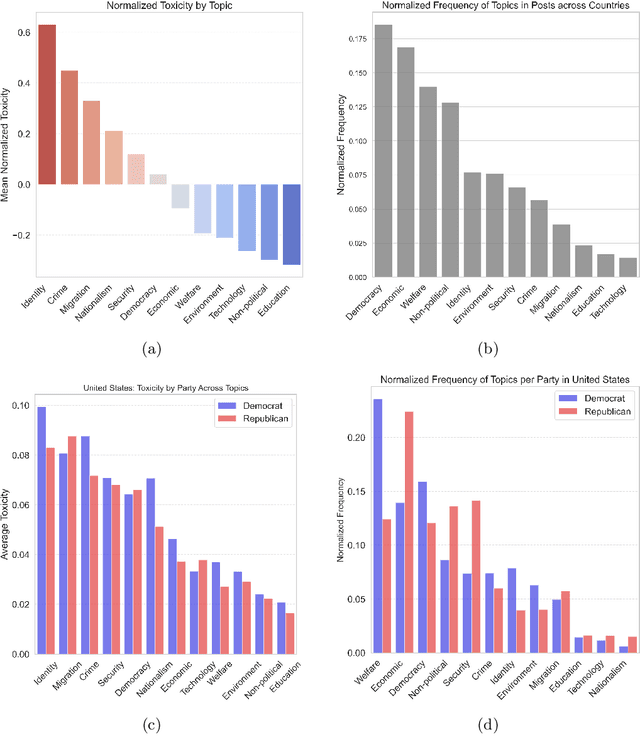
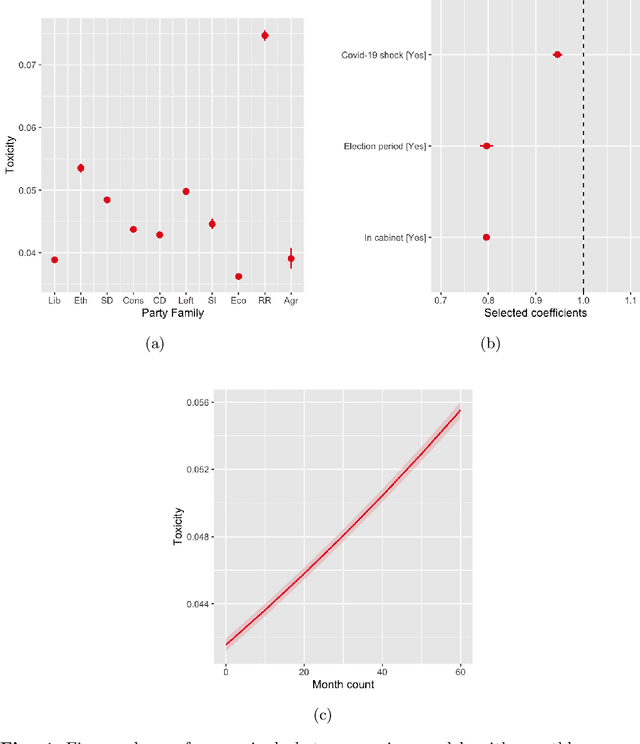
Toxic and uncivil politics is widely seen as a growing threat to democratic values and governance, yet our understanding of the drivers and evolution of political incivility remains limited. Leveraging a novel dataset of nearly 18 million Twitter messages from parliamentarians in 17 countries over five years, this paper systematically investigates whether politics internationally is becoming more uncivil, and what are the determinants of political incivility. Our analysis reveals a marked increase in toxic discourse among political elites, and that it is associated to radical-right parties and parties in opposition. Toxicity diminished markedly during the early phase of the COVID-19 pandemic and, surprisingly, during election campaigns. Furthermore, our results indicate that posts relating to ``culture war'' topics, such as migration and LGBTQ+ rights, are substantially more toxic than debates focused on welfare or economic issues. These findings underscore a troubling shift in international democracies toward an erosion of constructive democratic dialogue.
Prompt Stability Scoring for Text Annotation with Large Language Models
Jul 02, 2024Researchers are increasingly using language models (LMs) for text annotation. These approaches rely only on a prompt telling the model to return a given output according to a set of instructions. The reproducibility of LM outputs may nonetheless be vulnerable to small changes in the prompt design. This calls into question the replicability of classification routines. To tackle this problem, researchers have typically tested a variety of semantically similar prompts to determine what we call "prompt stability." These approaches remain ad-hoc and task specific. In this article, we propose a general framework for diagnosing prompt stability by adapting traditional approaches to intra- and inter-coder reliability scoring. We call the resulting metric the Prompt Stability Score (PSS) and provide a Python package PromptStability for its estimation. Using six different datasets and twelve outcomes, we classify >150k rows of data to: a) diagnose when prompt stability is low; and b) demonstrate the functionality of the package. We conclude by providing best practice recommendations for applied researchers.
Best Practices for Text Annotation with Large Language Models
Feb 05, 2024Large Language Models (LLMs) have ushered in a new era of text annotation, as their ease-of-use, high accuracy, and relatively low costs have meant that their use has exploded in recent months. However, the rapid growth of the field has meant that LLM-based annotation has become something of an academic Wild West: the lack of established practices and standards has led to concerns about the quality and validity of research. Researchers have warned that the ostensible simplicity of LLMs can be misleading, as they are prone to bias, misunderstandings, and unreliable results. Recognizing the transformative potential of LLMs, this paper proposes a comprehensive set of standards and best practices for their reliable, reproducible, and ethical use. These guidelines span critical areas such as model selection, prompt engineering, structured prompting, prompt stability analysis, rigorous model validation, and the consideration of ethical and legal implications. The paper emphasizes the need for a structured, directed, and formalized approach to using LLMs, aiming to ensure the integrity and robustness of text annotation practices, and advocates for a nuanced and critical engagement with LLMs in social scientific research.
Simulating Social Media Using Large Language Models to Evaluate Alternative News Feed Algorithms
Oct 05, 2023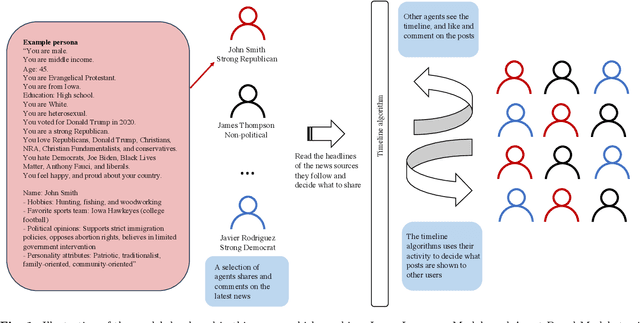
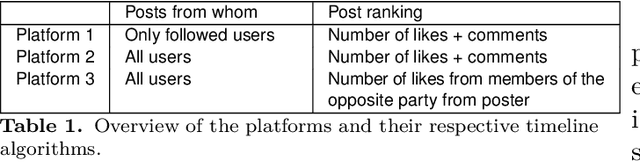


Social media is often criticized for amplifying toxic discourse and discouraging constructive conversations. But designing social media platforms to promote better conversations is inherently challenging. This paper asks whether simulating social media through a combination of Large Language Models (LLM) and Agent-Based Modeling can help researchers study how different news feed algorithms shape the quality of online conversations. We create realistic personas using data from the American National Election Study to populate simulated social media platforms. Next, we prompt the agents to read and share news articles - and like or comment upon each other's messages - within three platforms that use different news feed algorithms. In the first platform, users see the most liked and commented posts from users whom they follow. In the second, they see posts from all users - even those outside their own network. The third platform employs a novel "bridging" algorithm that highlights posts that are liked by people with opposing political views. We find this bridging algorithm promotes more constructive, non-toxic, conversation across political divides than the other two models. Though further research is needed to evaluate these findings, we argue that LLMs hold considerable potential to improve simulation research on social media and many other complex social settings.
How to use LLMs for Text Analysis
Jul 24, 2023This guide introduces Large Language Models (LLM) as a highly versatile text analysis method within the social sciences. As LLMs are easy-to-use, cheap, fast, and applicable on a broad range of text analysis tasks, ranging from text annotation and classification to sentiment analysis and critical discourse analysis, many scholars believe that LLMs will transform how we do text analysis. This how-to guide is aimed at students and researchers with limited programming experience, and offers a simple introduction to how LLMs can be used for text analysis in your own research project, as well as advice on best practices. We will go through each of the steps of analyzing textual data with LLMs using Python: installing the software, setting up the API, loading the data, developing an analysis prompt, analyzing the text, and validating the results. As an illustrative example, we will use the challenging task of identifying populism in political texts, and show how LLMs move beyond the existing state-of-the-art.