 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware Acceleration of LLMs: A comprehensive survey and comparison
Sep 05, 2024Large Language Models (LLMs) have emerged as powerful tools for natural language processing tasks, revolutionizing the field with their ability to understand and generate human-like text. In this paper, we present a comprehensive survey of the several research efforts that have been presented for the acceleration of transformer networks for Large Language Models using hardware accelerators. The survey presents the frameworks that have been proposed and then performs a qualitative and quantitative comparison regarding the technology, the processing platform (FPGA, ASIC, In-Memory, GPU), the speedup, the energy efficiency, the performance (GOPs), and the energy efficiency (GOPs/W) of each framework. The main challenge in comparison is that every proposed scheme is implemented on a different process technology making hard a fair comparison. The main contribution of this paper is that we extrapolate the results of the performance and the energy efficiency on the same technology to make a fair comparison; one theoretical and one more practical. We implement part of the LLMs on several FPGA chips to extrapolate the results to the same process technology and then we make a fair comparison of the performance.
A Survey on Hardware Accelerators for Large Language Models
Jan 18, 2024
Large Language Models (LLMs) have emerged as powerful tools for natural language processing tasks, revolutionizing the field with their ability to understand and generate human-like text. As the demand for more sophisticated LLMs continues to grow, there is a pressing need to address the computational challenges associated with their scale and complexity. This paper presents a comprehensive survey on hardware accelerators designed to enhance the performance and energy efficiency of Large Language Models. By examining a diverse range of accelerators, including GPUs, FPGAs, and custom-designed architectures, we explore the landscape of hardware solutions tailored to meet the unique computational demands of LLMs. The survey encompasses an in-depth analysis of architecture, performance metrics, and energy efficiency considerations, providing valuable insights for researchers, engineers, and decision-makers aiming to optimize the deployment of LLMs in real-world applications.
BrainFrame: A node-level heterogeneous accelerator platform for neuron simulations
Aug 15, 2017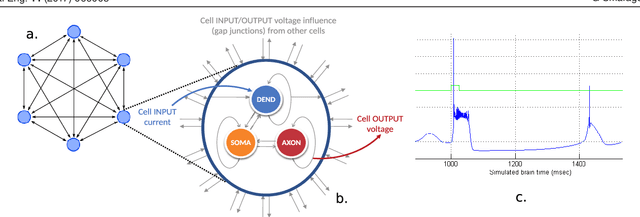

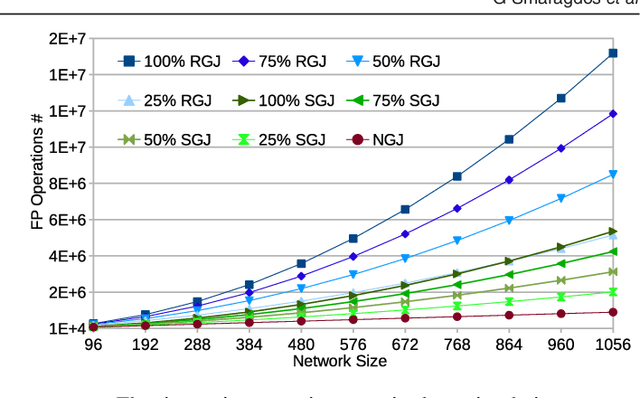

Objective: The advent of High-Performance Computing (HPC) in recent years has led to its increasing use in brain study through computational models. The scale and complexity of such models are constantly increasing, leading to challenging computational requirements. Even though modern HPC platforms can often deal with such challenges, the vast diversity of the modeling field does not permit for a single acceleration (or homogeneous) platform to effectively address the complete array of modeling requirements. Approach: In this paper we propose and build BrainFrame, a heterogeneous acceleration platform, incorporating three distinct acceleration technologies, a Dataflow Engine, a Xeon Phi and a GP-GPU. The PyNN framework is also integrated into the platform. As a challenging proof of concept, we analyze the performance of BrainFrame on different instances of a state-of-the-art neuron model, modeling the Inferior- Olivary Nucleus using a biophysically-meaningful, extended Hodgkin-Huxley representation. The model instances take into account not only the neuronal- network dimensions but also different network-connectivity circumstances that can drastically change application workload characteristics. Main results: The synthetic approach of three HPC technologies demonstrated that BrainFrame is better able to cope with the modeling diversity encountered. Our performance analysis shows clearly that the model directly affect performance and all three technologies are required to cope with all the model use cases.