 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThoughtSource: A central hub for large language model reasoning data
Jan 27, 2023Large language models (LLMs) such as GPT-3 and ChatGPT have recently demonstrated impressive results across a wide range of tasks. LLMs are still limited, however, in that they frequently fail at complex reasoning, their reasoning processes are opaque, they are prone to 'hallucinate' facts, and there are concerns about their underlying biases. Letting models verbalize reasoning steps as natural language, a technique known as chain-of-thought prompting, has recently been proposed as a way to address some of these issues. Here we present the first release of ThoughtSource, a meta-dataset and software library for chain-of-thought (CoT) reasoning. The goal of ThoughtSource is to improve future artificial intelligence systems by facilitating qualitative understanding of CoTs, enabling empirical evaluations, and providing training data. This first release of ThoughtSource integrates six scientific/medical, three general-domain and five math word question answering datasets.
Can large language models reason about medical questions?
Jul 17, 2022
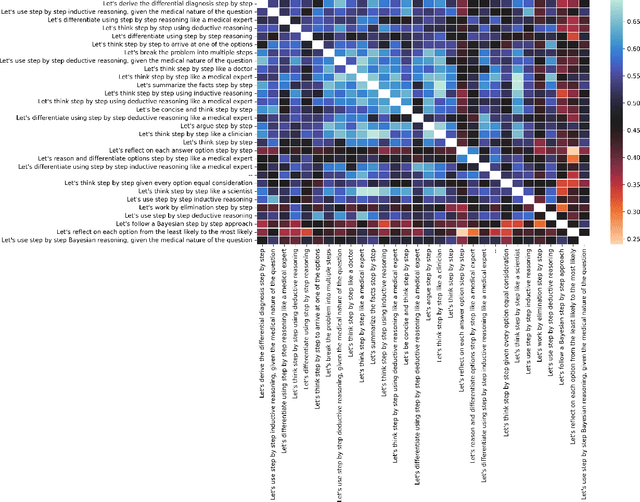

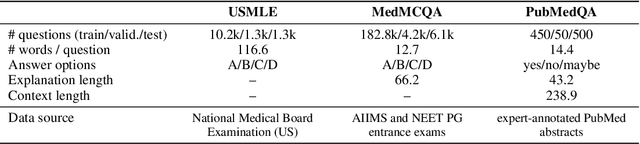
Although large language models (LLMs) often produce impressive outputs, they also fail to reason and be factual. We set out to investigate how these limitations affect the LLM's ability to answer and reason about difficult real-world based questions. We applied the human-aligned GPT-3 (InstructGPT) to answer multiple-choice medical exam questions (USMLE and MedMCQA) and medical research questions (PubMedQA). We investigated Chain-of-thought (think step by step) prompts, grounding (augmenting the prompt with search results) and few-shot (prepending the question with question-answer exemplars). For a subset of the USMLE questions, a medical domain expert reviewed and annotated the model's reasoning. Overall, GPT-3 achieved a substantial improvement in state-of-the-art machine learning performance. We observed that GPT-3 is often knowledgeable and can reason about medical questions. GPT-3, when confronted with a question it cannot answer, will still attempt to answer, often resulting in a biased predictive distribution. LLMs are not on par with human performance but our results suggest the emergence of reasoning patterns that are compatible with medical problem-solving. We speculate that scaling model and data, enhancing prompt alignment and allowing for better contextualization of the completions will be sufficient for LLMs to reach human-level performance on this type of task.