 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Compositional Attention Networks for Social Reasoning in Videos
Oct 03, 2022
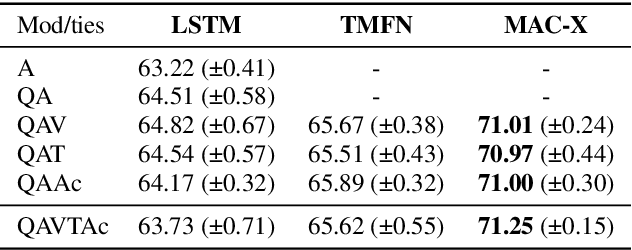


We propose a novel deep architecture for the task of reasoning about social interactions in videos. We leverage the multi-step reasoning capabilities of Compositional Attention Networks (MAC), and propose a multimodal extension (MAC-X). MAC-X is based on a recurrent cell that performs iterative mid-level fusion of input modalities (visual, auditory, text) over multiple reasoning steps, by use of a temporal attention mechanism. We then combine MAC-X with LSTMs for temporal input processing in an end-to-end architecture. Our ablation studies show that the proposed MAC-X architecture can effectively leverage multimodal input cues using mid-level fusion mechanisms. We apply MAC-X to the task of Social Video Question Answering in the Social IQ dataset and obtain a 2.5% absolute improvement in terms of binary accuracy over the current state-of-the-art.