 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic vocal tract landmark localization from midsagittal MRI data
Jul 18, 2019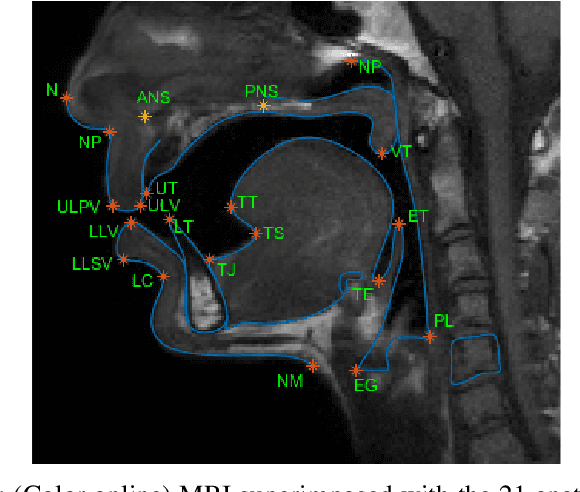
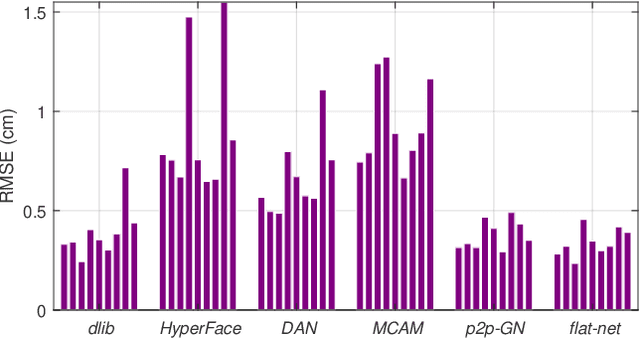
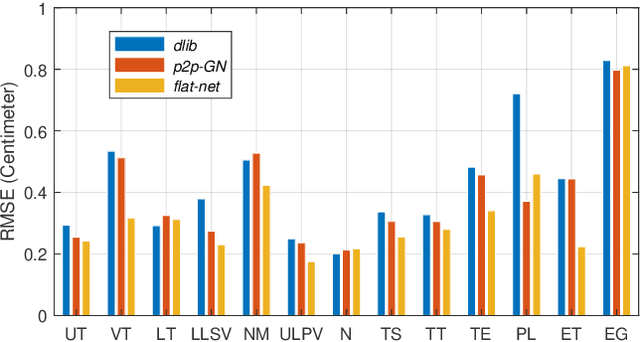
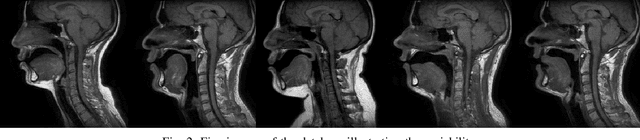
The various speech sounds of a language are obtained by varying the shape and position of the articulators surrounding the vocal tract. Analyzing their variability is crucial for understanding speech production, diagnosing speech and swallowing disorders and building intuitive applications for rehabilitation. Magnetic Resonance Imaging (MRI) is currently the most harmless powerful imaging modality used for this purpose. Identifying key anatomical landmarks on it is a pre-requisite for further analyses. This is a challenging task considering the high inter- and intra-speaker variability and the mutual interaction between the articulators. This study intends to solve this issue automatically for the first time. For this purpose, midsagittal anatomical MRI for 9 speakers sustaining 62 articulations and annotated with the location of 21 key anatomical landmarks are considered. Four state-of-the-art methods, including deep learning methods, are adapted from the literature for facial landmark localization and human pose estimation and evaluated. Furthermore, an approach based on the description of each landmark location as a heat-map image stored in a channel of a single multi-channel image embedding all landmarks is proposed. The generation of such a multi-channel image from an input MRI image is tested through two deep learning networks, one taken from the literature and one designed on purpose in this study, the flat-net. Results show that the flat-net approach outperforms the other methods, leading to an overall Root Mean Square Error of 3.4~pixels/0.34~cm obtained in a leave-one-out procedure over the speakers. All of the codes are publicly available on GitHub.