 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Morphology and Lexicography Modeling of Modern Standard Arabic Nominals
Feb 01, 2024Modern Standard Arabic (MSA) nominals present many morphological and lexical modeling challenges that have not been consistently addressed previously. This paper attempts to define the space of such challenges, and leverage a recently proposed morphological framework to build a comprehensive and extensible model for MSA nominals. Our model design addresses the nominals' intricate morphotactics, as well as their paradigmatic irregularities. Our implementation showcases enhanced accuracy and consistency compared to a commonly used MSA morphological analyzer and generator. We make our models publicly available.
Advancements in Arabic Grammatical Error Detection and Correction: An Empirical Investigation
May 24, 2023Grammatical error correction (GEC) is a well-explored problem in English with many existing models and datasets. However, research on GEC in morphologically rich languages has been limited due to challenges such as data scarcity and language complexity. In this paper, we present the first results on Arabic GEC by using two newly developed Transformer-based pretrained sequence-to-sequence models. We address the task of multi-class Arabic grammatical error detection (GED) and present the first results on multi-class Arabic GED. We show that using GED information as auxiliary input in GEC models improves GEC performance across three datasets spanning different genres. Moreover, we also investigate the use of contextual morphological preprocessing in aiding GEC systems. Our models achieve state-of-the-art results on two Arabic GEC shared tasks datasets and establish a strong benchmark on a newly created dataset.
Maknuune: A Large Open Palestinian Arabic Lexicon
Oct 24, 2022
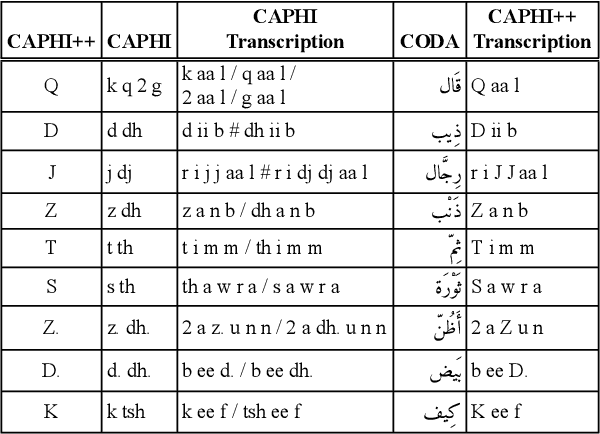

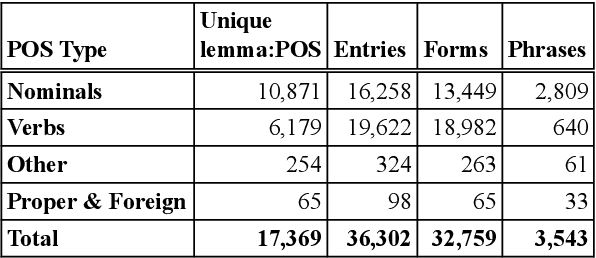
We present Maknuune, a large open lexicon for the Palestinian Arabic dialect. Maknuune has over 36K entries from 17K lemmas, and 3.7K roots. All entries include diacritized Arabic orthography, phonological transcription and English glosses. Some entries are enriched with additional information such as broken plurals and templatic feminine forms, associated phrases and collocations, Standard Arabic glosses, and examples or notes on grammar, usage, or location of collected entry.