 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explainable and Conformal AI Model to Detect Temporomandibular Joint Involvement in Children Suffering from Juvenile Idiopathic Arthritis
May 02, 2024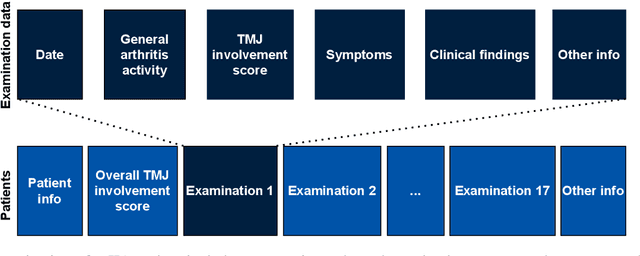
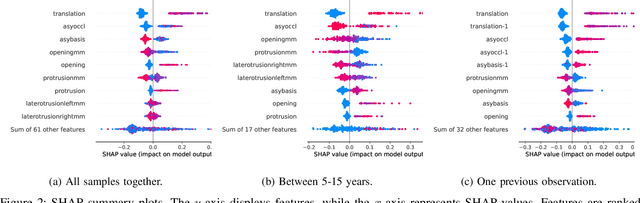

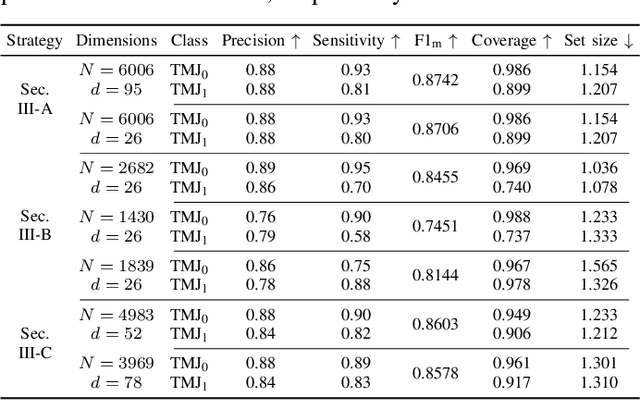
Juvenile idiopathic arthritis (JIA) is the most common rheumatic disease during childhood and adolescence. The temporomandibular joints (TMJ) are among the most frequently affected joints in patients with JIA, and mandibular growth is especially vulnerable to arthritic changes of the TMJ in children. A clinical examination is the most cost-effective method to diagnose TMJ involvement, but clinicians find it difficult to interpret and inaccurate when used only on clinical examinations. This study implemented an explainable artificial intelligence (AI) model that can help clinicians assess TMJ involvement. The classification model was trained using Random Forest on 6154 clinical examinations of 1035 pediatric patients (67% female, 33% male) and evaluated on its ability to correctly classify TMJ involvement or not on a separate test set. Most notably, the results show that the model can classify patients within two years of their first examination as having TMJ involvement with a precision of 0.86 and a sensitivity of 0.7. The results show promise for an AI model in the assessment of TMJ involvement in children and as a decision support tool.
A probabilistic estimation of remaining useful life from censored time-to-event data
May 02, 2024Predicting the remaining useful life (RUL) of ball bearings plays an important role in predictive maintenance. A common definition of the RUL is the time until a bearing is no longer functional, which we denote as an event, and many data-driven methods have been proposed to predict the RUL. However, few studies have addressed the problem of censored data, where this event of interest is not observed, and simply ignoring these observations can lead to an overestimation of the failure risk. In this paper, we propose a probabilistic estimation of RUL using survival analysis that supports censored data. First, we analyze sensor readings from ball bearings in the frequency domain and annotate when a bearing starts to deteriorate by calculating the Kullback-Leibler (KL) divergence between the probability density function (PDF) of the current process and a reference PDF. Second, we train several survival models on the annotated bearing dataset, capable of predicting the RUL over a finite time horizon using the survival function. This function is guaranteed to be strictly monotonically decreasing and is an intuitive estimation of the remaining lifetime. We demonstrate our approach in the XJTU-SY dataset using cross-validation and find that Random Survival Forests consistently outperforms both non-neural networks and neural networks in terms of the mean absolute error (MAE). Our work encourages the inclusion of censored data in predictive maintenance models and highlights the unique advantages that survival analysis offers when it comes to probabilistic RUL estimation and early fault detection.
Probabilistic Survival Analysis by Approximate Bayesian Inference of Neural Networks
Apr 12, 2024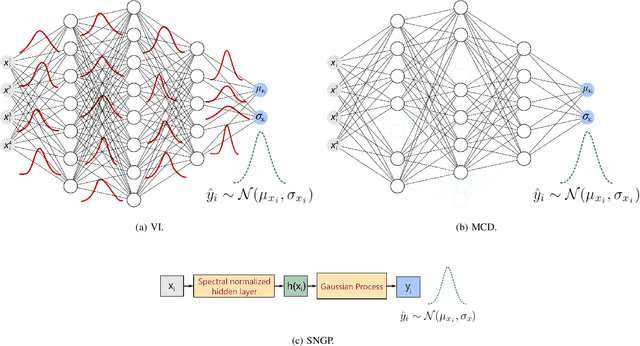
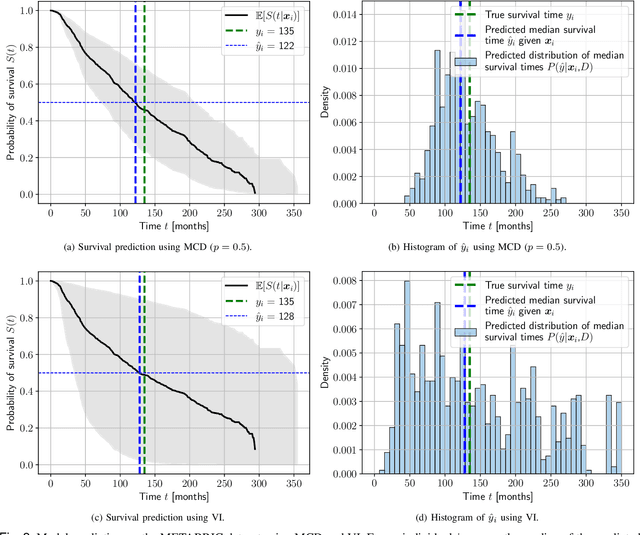
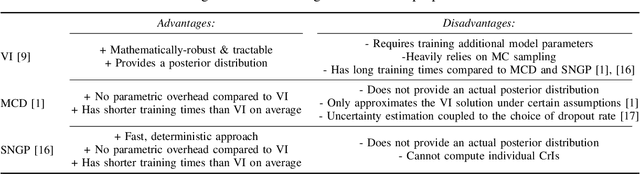
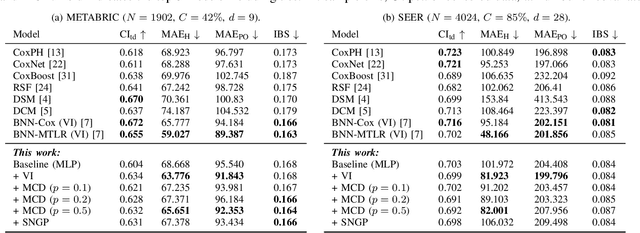
Predicting future events always comes with uncertainty, but traditional non-probabilistic methods cannot distinguish certain from uncertain predictions. In survival analysis, probabilistic methods applied to state-of-the-art solutions in the healthcare and biomedical field are still novel, and their implications have not been fully evaluated. In this paper, we study the benefits of modeling uncertainty in deep neural networks for survival analysis with a focus on prediction and calibration performance. For this, we present a Bayesian deep learning framework that consists of three probabilistic network architectures, which we train by optimizing the Cox partial likelihood and combining input-dependent aleatoric uncertainty together with epistemic uncertainty. This enables us to provide uncertainty estimates as credible intervals when predicting the survival curve or as a probability density function over the predicted median survival times. For our empirical analyses, we evaluated our proposed method on four benchmark datasets and found that our method demonstrates prediction performance comparable to the state-of-the-art based on the concordance index and outperforms all other Cox-based approaches in terms of the mean absolute error. Our work explicitly compares the extent to which different Bayesian approximation techniques differ from each other and improves the prediction over traditional non-probabilistic alternatives.
Predicting Survival Time of Ball Bearings in the Presence of Censoring
Sep 13, 2023Ball bearings find widespread use in various manufacturing and mechanical domains, and methods based on machine learning have been widely adopted in the field to monitor wear and spot defects before they lead to failures. Few studies, however, have addressed the problem of censored data, in which failure is not observed. In this paper, we propose a novel approach to predict the time to failure in ball bearings using survival analysis. First, we analyze bearing data in the frequency domain and annotate when a bearing fails by comparing the Kullback-Leibler divergence and the standard deviation between its break-in frequency bins and its break-out frequency bins. Second, we train several survival models to estimate the time to failure based on the annotated data and covariates extracted from the time domain, such as skewness, kurtosis and entropy. The models give a probabilistic prediction of risk over time and allow us to compare the survival function between groups of bearings. We demonstrate our approach on the XJTU and PRONOSTIA datasets. On XJTU, the best result is a 0.70 concordance-index and 0.21 integrated Brier score. On PRONOSTIA, the best is a 0.76 concordance-index and 0.19 integrated Brier score. Our work motivates further work on incorporating censored data in models for predictive maintenance.
Computationally Efficient Labeling of Cancer Related Forum Posts by Non-Clinical Text Information Retrieval
Mar 24, 2023An abundance of information about cancer exists online, but categorizing and extracting useful information from it is difficult. Almost all research within healthcare data processing is concerned with formal clinical data, but there is valuable information in non-clinical data too. The present study combines methods within distributed computing, text retrieval, clustering, and classification into a coherent and computationally efficient system, that can clarify cancer patient trajectories based on non-clinical and freely available information. We produce a fully-functional prototype that can retrieve, cluster and present information about cancer trajectories from non-clinical forum posts. We evaluate three clustering algorithms (MR-DBSCAN, DBSCAN, and HDBSCAN) and compare them in terms of Adjusted Rand Index and total run time as a function of the number of posts retrieved and the neighborhood radius. Clustering results show that neighborhood radius has the most significant impact on clustering performance. For small values, the data set is split accordingly, but high values produce a large number of possible partitions and searching for the best partition is hereby time-consuming. With a proper estimated radius, MR-DBSCAN can cluster 50000 forum posts in 46.1 seconds, compared to DBSCAN (143.4) and HDBSCAN (282.3). We conduct an interview with the Danish Cancer Society and present our software prototype. The organization sees a potential in software that can democratize online information about cancer and foresee that such systems will be required in the future.
Cloud K-SVD for Image Denoising
Mar 01, 2023Cloud K-SVD is a dictionary learning algorithm that can train at multiple nodes and hereby produce a mutual dictionary to represent low-dimensional geometric structures in image data. We present a novel application of the algorithm as we use it to recover both noiseless and noisy images from overlapping patches. We implement a node network in Kubernetes using Docker containers to facilitate Cloud K-SVD. Results show that Cloud K-SVD can recover images approximately and remove quantifiable amounts of noise from benchmark gray-scaled images without sacrificing accuracy in recovery; we achieve an SSIM index of 0.88, 0.91 and 0.95 between clean and recovered images for noise levels ($\mu$ = 0, $\sigma^{2}$ = 0.01, 0.005, 0.001), respectively, which is similar to SOTA in the field. Cloud K-SVD is evidently able to learn a mutual dictionary across multiple nodes and remove AWGN from images. The mutual dictionary can be used to recover a specific image at any of the nodes in the network.
Not all noise is accounted equally: How differentially private learning benefits from large sampling rates
Oct 12, 2021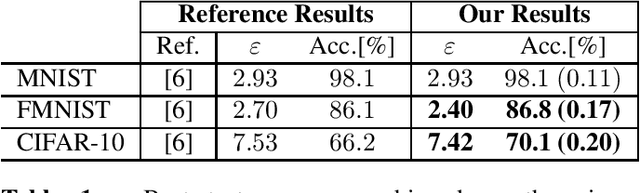
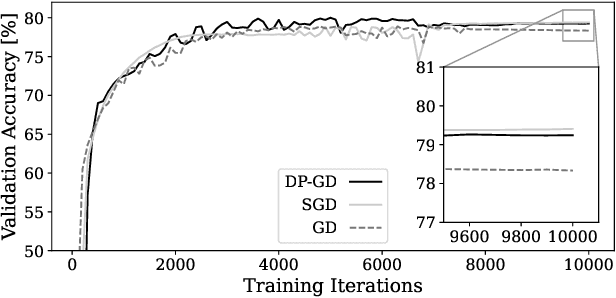
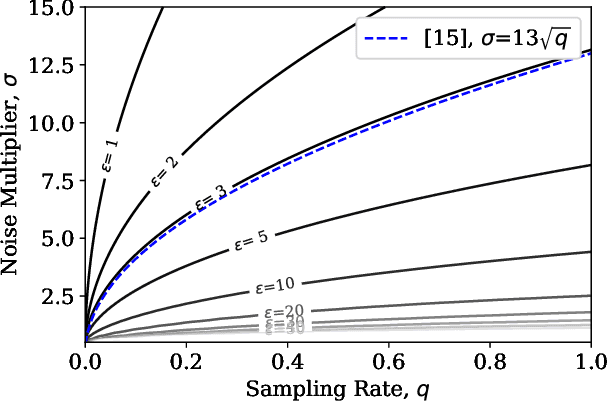
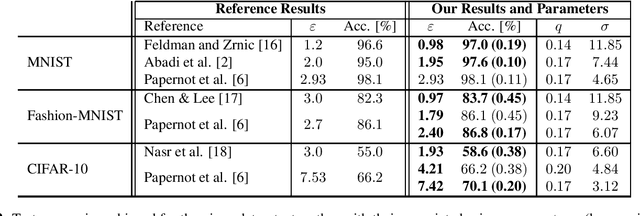
Learning often involves sensitive data and as such, privacy preserving extensions to Stochastic Gradient Descent (SGD) and other machine learning algorithms have been developed using the definitions of Differential Privacy (DP). In differentially private SGD, the gradients computed at each training iteration are subject to two different types of noise. Firstly, inherent sampling noise arising from the use of minibatches. Secondly, additive Gaussian noise from the underlying mechanisms that introduce privacy. In this study, we show that these two types of noise are equivalent in their effect on the utility of private neural networks, however they are not accounted for equally in the privacy budget. Given this observation, we propose a training paradigm that shifts the proportions of noise towards less inherent and more additive noise, such that more of the overall noise can be accounted for in the privacy budget. With this paradigm, we are able to improve on the state-of-the-art in the privacy/utility tradeoff of private end-to-end CNNs.
Super-convergence and Differential Privacy: Training faster with better privacy guarantees
Mar 18, 2021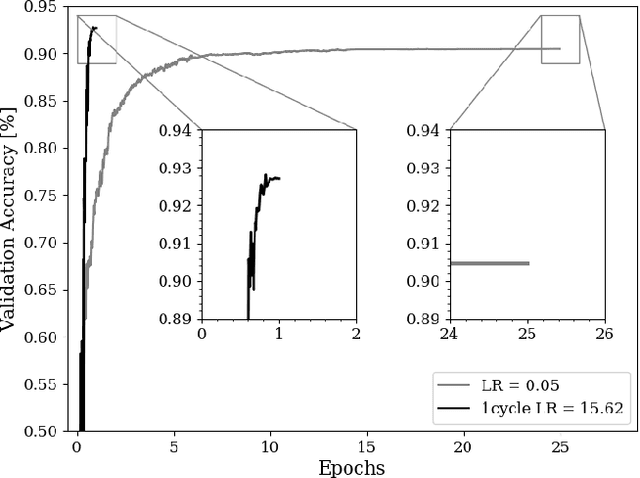
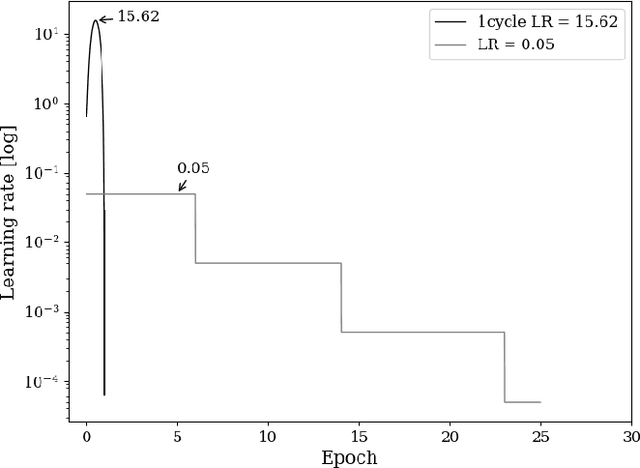
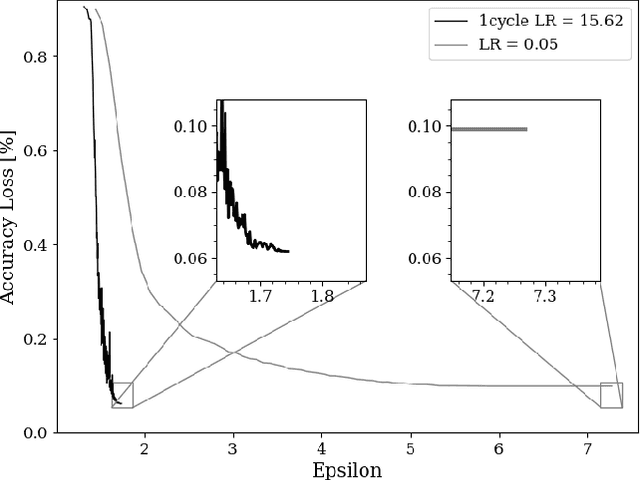
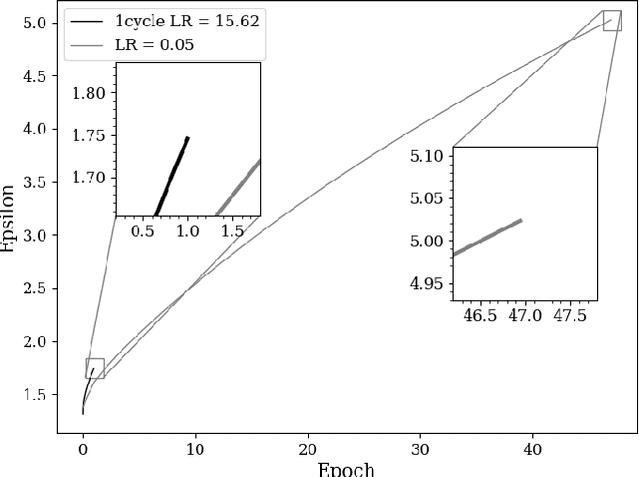
The combination of deep neural networks and Differential Privacy has been of increasing interest in recent years, as it offers important data protection guarantees to the individuals of the training datasets used. However, using Differential Privacy in the training of neural networks comes with a set of shortcomings, like a decrease in validation accuracy and a significant increase in the use of resources and time in training. In this paper, we examine super-convergence as a way of greatly increasing training speed of differentially private neural networks, addressing the shortcoming of high training time and resource use. Super-convergence allows for acceleration in network training using very high learning rates, and has been shown to achieve models with high utility in orders of magnitude less training iterations than conventional ways. Experiments in this paper show that this order-of-magnitude speedup can also be seen when combining it with Differential Privacy, allowing for higher validation accuracies in much fewer training iterations compared to non-private, non-super convergent baseline models. Furthermore, super-convergence is shown to improve the privacy guarantees of private models.