 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot all noise is accounted equally: How differentially private learning benefits from large sampling rates
Paper and Code
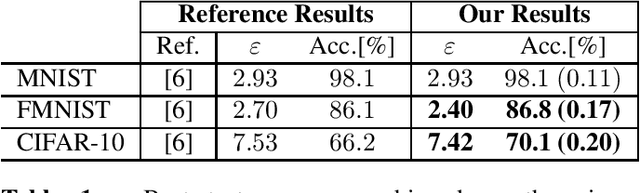
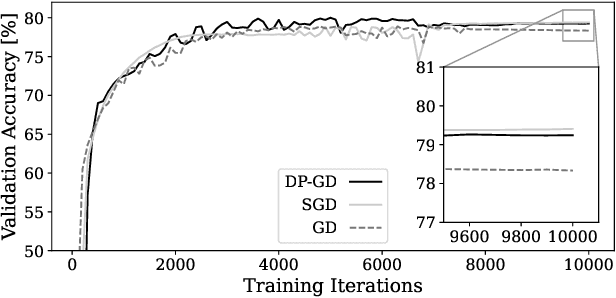
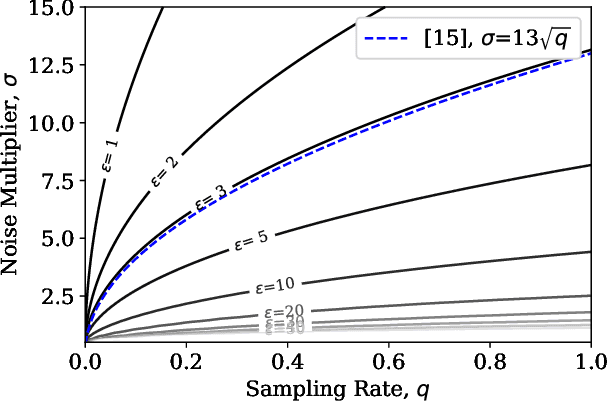
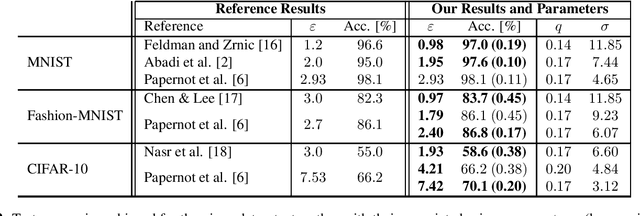
Learning often involves sensitive data and as such, privacy preserving extensions to Stochastic Gradient Descent (SGD) and other machine learning algorithms have been developed using the definitions of Differential Privacy (DP). In differentially private SGD, the gradients computed at each training iteration are subject to two different types of noise. Firstly, inherent sampling noise arising from the use of minibatches. Secondly, additive Gaussian noise from the underlying mechanisms that introduce privacy. In this study, we show that these two types of noise are equivalent in their effect on the utility of private neural networks, however they are not accounted for equally in the privacy budget. Given this observation, we propose a training paradigm that shifts the proportions of noise towards less inherent and more additive noise, such that more of the overall noise can be accounted for in the privacy budget. With this paradigm, we are able to improve on the state-of-the-art in the privacy/utility tradeoff of private end-to-end CNNs.