 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStream-Based Active Learning for Process Monitoring
Nov 19, 2024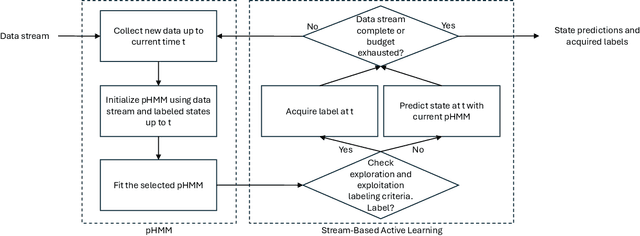
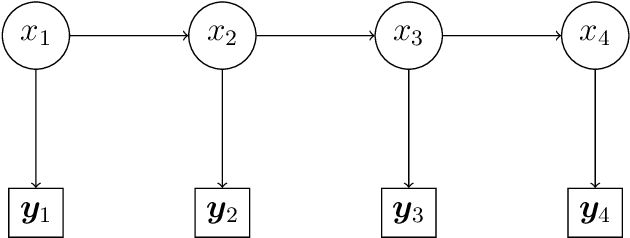
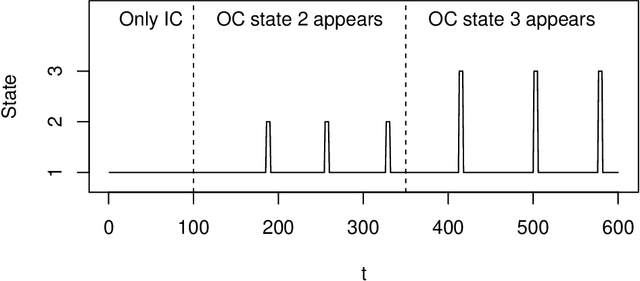
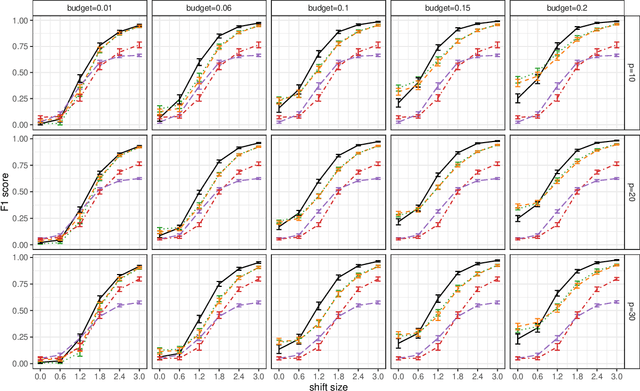
Statistical process monitoring (SPM) methods are essential tools in quality management to check the stability of industrial processes, i.e., to dynamically classify the process state as in control (IC), under normal operating conditions, or out of control (OC), otherwise. Traditional SPM methods are based on unsupervised approaches, which are popular because in most industrial applications the true OC states of the process are not explicitly known. This hampered the development of supervised methods that could instead take advantage of process data containing labels on the true process state, although they still need improvement in dealing with class imbalance, as OC states are rare in high-quality processes, and the dynamic recognition of unseen classes, e.g., the number of possible OC states. This article presents a novel stream-based active learning strategy for SPM that enhances partially hidden Markov models to deal with data streams. The ultimate goal is to optimize labeling resources constrained by a limited budget and dynamically update the possible OC states. The proposed method performance in classifying the true state of the process is assessed through a simulation and a case study on the SPM of a resistance spot welding process in the automotive industry, which motivated this research.
Additive stacking for disaggregate electricity demand forecasting
May 20, 2020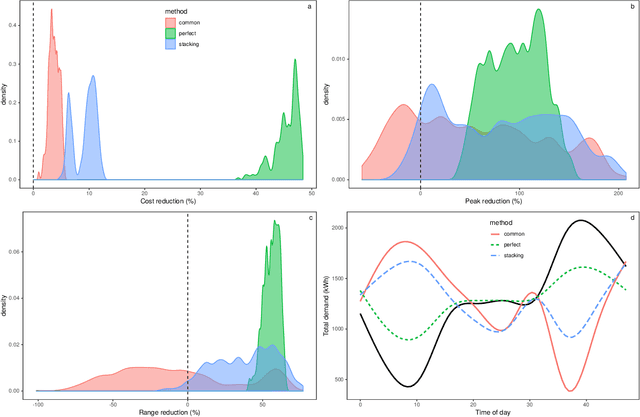
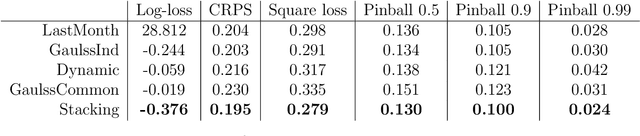
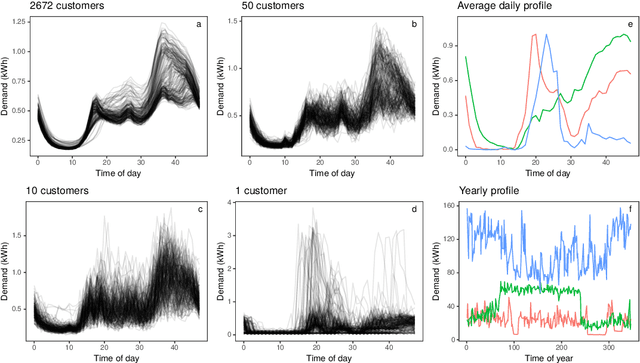
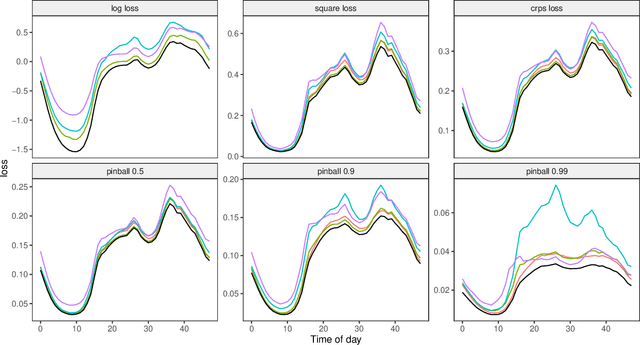
Future grid management systems will coordinate distributed production and storage resources to manage, in a cost effective fashion, the increased load and variability brought by the electrification of transportation and by a higher share of weather dependent production. Electricity demand forecasts at a low level of aggregation will be key inputs for such systems. We focus on forecasting demand at the individual household level, which is more challenging than forecasting aggregate demand, due to the lower signal-to-noise ratio and to the heterogeneity of consumption patterns across households. We propose a new ensemble method for probabilistic forecasting, which borrows strength across the households while accommodating their individual idiosyncrasies. In particular, we develop a set of models or 'experts' which capture different demand dynamics and we fit each of them to the data from each household. Then we construct an aggregation of experts where the ensemble weights are estimated on the whole data set, the main innovation being that we let the weights vary with the covariates by adopting an additive model structure. In particular, the proposed aggregation method is an extension of regression stacking (Breiman, 1996) where the mixture weights are modelled using linear combinations of parametric, smooth or random effects. The methods for building and fitting additive stacking models are implemented by the gamFactory R package, available at https://github.com/mfasiolo/gamFactory.