 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEDNet: Shallow Encoder-Decoder Network for Brain Tumor Segmentation
Jan 24, 2024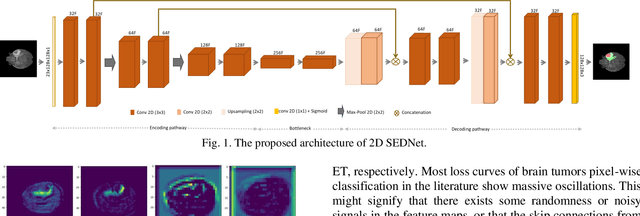
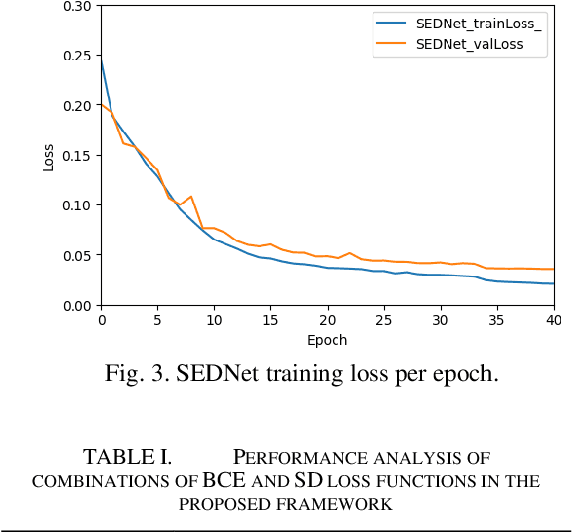
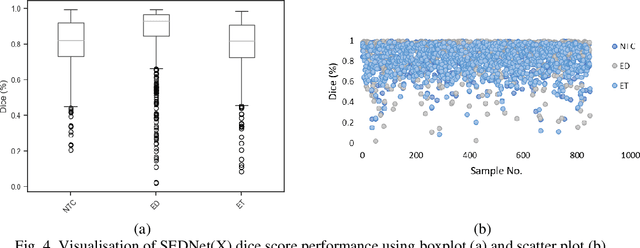
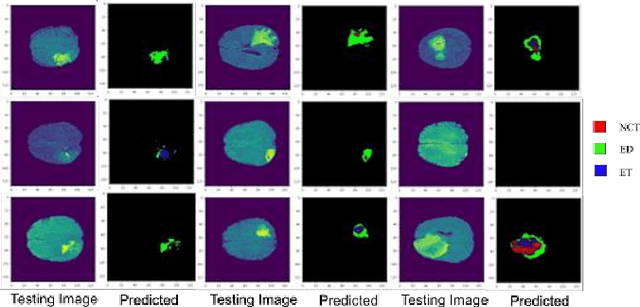
Despite the advancement in computational modeling towards brain tumor segmentation, of which several models have been developed, it is evident from the computational complexity of existing models which are still at an all-time high, that performance and efficiency under clinical application scenarios are limited. Therefore, this paper proposes a shallow encoder and decoder network named SEDNet for brain tumor segmentation. The proposed network is adapted from the U-Net structure. Though brain tumors do not assume complex structures like the task the traditional U-Net was designed for, their variance in appearance, shape, and ambiguity of boundaries makes it a compelling complex task to solve. SEDNet architecture design is inspired by the localized nature of brain tumors in brain images, thus consists of sufficient hierarchical convolutional blocks in the encoding pathway capable of learning the intrinsic features of brain tumors in brain slices, and a decoding pathway with selective skip path sufficient for capturing miniature local-level spatial features alongside the global-level features of brain tumor. SEDNet with the integration of the proposed preprocessing algorithm and optimization function on the BraTS2020 set reserved for testing achieves impressive dice and Hausdorff scores of 0.9308, 0.9451, 0.9026, and 0.7040, 1.2866, 0.7762 for non-enhancing tumor core (NTC), peritumoral edema (ED), and enhancing tumor (ET), respectively. Furthermore, through transfer learning with initialized SEDNet pre-trained weights, termed SEDNetX, a performance increase is observed. The dice and Hausdorff scores recorded are 0.9336, 0.9478, 0.9061, 0.6983, 1.2691, and 0.7711 for NTC, ED, and ET, respectively. With about 1.3 million parameters and impressive performance in comparison to the state-of-the-art, SEDNet(X) is shown to be computationally efficient for real-time clinical diagnosis.
Structure-focused Neurodegeneration Convolutional Neural Network for Modeling and Classification of Alzheimer's Disease
Jan 10, 2024Alzheimer's disease (AD), the predominant form of dementia, poses a growing global challenge and underscores the urgency of accurate and early diagnosis. The clinical technique radiologists adopt for distinguishing between mild cognitive impairment (MCI) and AD using Machine Resonance Imaging (MRI) encounter hurdles because they are not consistent and reliable. Machine learning has been shown to offer promise for early AD diagnosis. However, existing models focused on focal fine-grain features without considerations to focal structural features that give off information on neurodegeneration of the brain cerebral cortex. Therefore, this paper proposes a machine learning (ML) framework that integrates Gamma correction, an image enhancement technique, and includes a structure-focused neurodegeneration convolutional neural network (CNN) architecture called SNeurodCNN for discriminating between AD and MCI. The ML framework leverages the mid-sagittal and para-sagittal brain image viewpoints of the structure-focused Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset. Through experiments, our proposed machine learning framework shows exceptional performance. The parasagittal viewpoint set achieves 97.8% accuracy, with 97.0% specificity and 98.5% sensitivity. The midsagittal viewpoint is shown to present deeper insights into the structural brain changes given the increase in accuracy, specificity, and sensitivity, which are 98.1% 97.2%, and 99.0%, respectively. Using GradCAM technique, we show that our proposed model is capable of capturing the structural dynamics of MCI and AD which exist about the frontal lobe, occipital lobe, cerebellum, and parietal lobe. Therefore, our model itself as a potential brain structural change Digi-Biomarker for early diagnosis of AD.
Convolutional Neural Network Ensemble Learning for Hyperspectral Imaging-based Blackberry Fruit Ripeness Detection in Uncontrolled Farm Environment
Jan 09, 2024



Fruit ripeness estimation models have for decades depended on spectral index features or colour-based features, such as mean, standard deviation, skewness, colour moments, and/or histograms for learning traits of fruit ripeness. Recently, few studies have explored the use of deep learning techniques to extract features from images of fruits with visible ripeness cues. However, the blackberry (Rubus fruticosus) fruit does not show obvious and reliable visible traits of ripeness when mature and therefore poses great difficulty to fruit pickers. The mature blackberry, to the human eye, is black before, during, and post-ripening. To address this engineering application challenge, this paper proposes a novel multi-input convolutional neural network (CNN) ensemble classifier for detecting subtle traits of ripeness in blackberry fruits. The multi-input CNN was created from a pre-trained visual geometry group 16-layer deep convolutional network (VGG16) model trained on the ImageNet dataset. The fully connected layers were optimized for learning traits of ripeness of mature blackberry fruits. The resulting model served as the base for building homogeneous ensemble learners that were ensemble using the stack generalization ensemble (SGE) framework. The input to the network is images acquired with a stereo sensor using visible and near-infrared (VIS-NIR) spectral filters at wavelengths of 700 nm and 770 nm. Through experiments, the proposed model achieved 95.1% accuracy on unseen sets and 90.2% accuracy with in-field conditions. Further experiments reveal that machine sensory is highly and positively correlated to human sensory over blackberry fruit skin texture.
Consensus-Threshold Criterion for Offline Signature Verification using Convolutional Neural Network Learned Representations
Jan 05, 2024A genuine signer's signature is naturally unstable even at short time-intervals whereas, expert forgers always try to perfectly mimic a genuine signer's signature. This presents a challenge which puts a genuine signer at risk of being denied access, while a forge signer is granted access. The implication is a high false acceptance rate (FAR) which is the percentage of forge signature classified as belonging to a genuine class. Existing work have only scratched the surface of signature verification because the misclassification error remains high. In this paper, a consensus-threshold distance-based classifier criterion is proposed for offline writer-dependent signature verification. Using features extracted from SigNet and SigNet-F deep convolutional neural network models, the proposed classifier minimizes FAR. This is demonstrated via experiments on four datasets: GPDS-300, MCYT, CEDAR and Brazilian PUC-PR datasets. On GPDS-300, the consensus threshold classifier improves the state-of-the-art performance by achieving a 1.27% FAR compared to 8.73% and 17.31% recorded in literature. This performance is consistent across other datasets and guarantees that the risk of imposters gaining access to sensitive documents or transactions is minimal.
Understanding Unconventional Preprocessors in Deep Convolutional Neural Networks for Face Identification
May 02, 2019

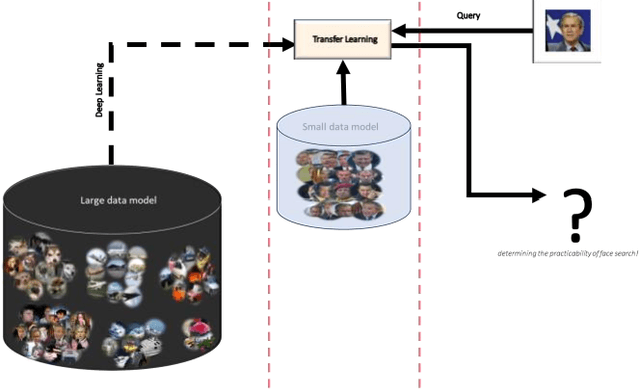

Deep networks have achieved huge successes in application domains like object and face recognition. The performance gain is attributed to different facets of the network architecture such as: depth of the convolutional layers, activation function, pooling, batch normalization, forward and back propagation and many more. However, very little emphasis is made on the preprocessors. Therefore, in this paper, the network's preprocessing module is varied across different preprocessing approaches while keeping constant other facets of the network architecture, to investigate the contribution preprocessing makes to the network. Commonly used preprocessors are the data augmentation and normalization and are termed conventional preprocessors. Others are termed the unconventional preprocessors, they are: color space converters; HSV, CIE L*a*b* and YCBCR, grey-level resolution preprocessors; full-based and plane-based image quantization, illumination normalization and insensitive feature preprocessing using: histogram equalization (HE), local contrast normalization (LN) and complete face structural pattern (CFSP). To achieve fixed network parameters, CNNs with transfer learning is employed. Knowledge from the high-level feature vectors of the Inception-V3 network is transferred to offline preprocessed LFW target data; and features trained using the SoftMax classifier for face identification. The experiments show that the discriminative capability of the deep networks can be improved by preprocessing RGB data with HE, full-based and plane-based quantization, rgbGELog, and YCBCR, preprocessors before feeding it to CNNs. However, for best performance, the right setup of preprocessed data with augmentation and/or normalization is required. The plane-based image quantization is found to increase the homogeneity of neighborhood pixels and utilizes reduced bit depth for better storage efficiency.
Expressing Facial Structure and Appearance Information in Frequency Domain for Face Recognition
Apr 28, 2017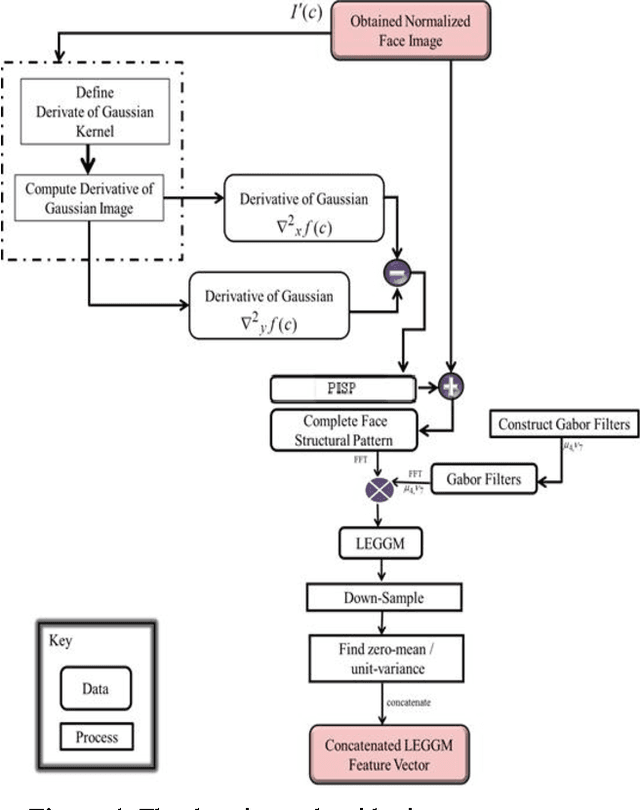

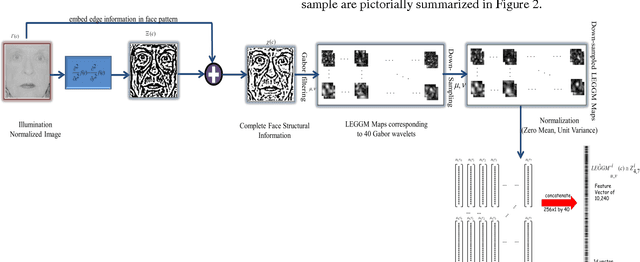
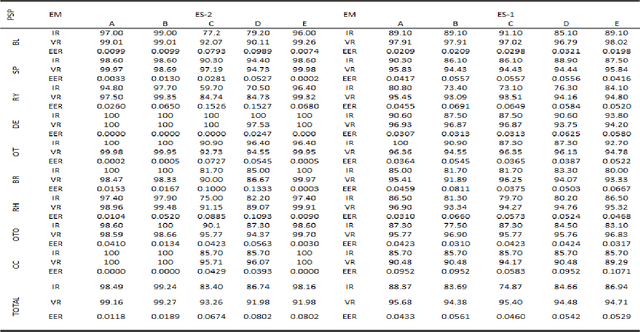
Beneath the uncertain primitive visual features of face images are the primitive intrinsic structural patterns (PISP) essential for characterizing a sample face discriminative attributes. It is on this basis that this paper presents a simple yet effective facial descriptor formed from derivatives of Gaussian and Gabor Wavelets. The new descriptor is coined local edge gradient Gabor magnitude (LEGGM) pattern. LEGGM first uncovers the PISP locked in every pixel through determining the pixel gradient in relation to its neighbors using the Derivatives of Gaussians. Then, the resulting output is embedded into the global appearance of the face which are further processed using Gabor wavelets in order to express its frequency characteristics. Additionally, we adopted various subspace models for dimensionality reduction in order to ascertain the best fit model for reporting a more effective representation of the LEGGM patterns. The proposed descriptor-based face recognition method is evaluated on three databases: Plastic surgery, LFW, and GT face databases. Through experiments, using a base classifier, the efficacy of the proposed method is demonstrated, especially in the case of plastic surgery database. The heterogeneous database, which we created to typify real-world scenario, show that the proposed method is to an extent insensitive to image formation factors with impressive recognition performances.