 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid training of Hamiltonian graph networks without gradient descent
Jun 06, 2025Learning dynamical systems that respect physical symmetries and constraints remains a fundamental challenge in data-driven modeling. Integrating physical laws with graph neural networks facilitates principled modeling of complex N-body dynamics and yields accurate and permutation-invariant models. However, training graph neural networks with iterative, gradient-based optimization algorithms (e.g., Adam, RMSProp, LBFGS) often leads to slow training, especially for large, complex systems. In comparison to 15 different optimizers, we demonstrate that Hamiltonian Graph Networks (HGN) can be trained up to 600x faster--but with comparable accuracy--by replacing iterative optimization with random feature-based parameter construction. We show robust performance in diverse simulations, including N-body mass-spring systems in up to 3 dimensions with different geometries, while retaining essential physical invariances with respect to permutation, rotation, and translation. We reveal that even when trained on minimal 8-node systems, the model can generalize in a zero-shot manner to systems as large as 4096 nodes without retraining. Our work challenges the dominance of iterative gradient-descent-based optimization algorithms for training neural network models for physical systems.
Training Hamiltonian neural networks without backpropagation
Nov 26, 2024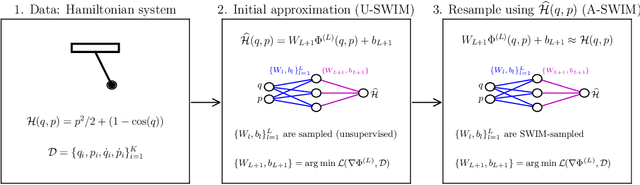
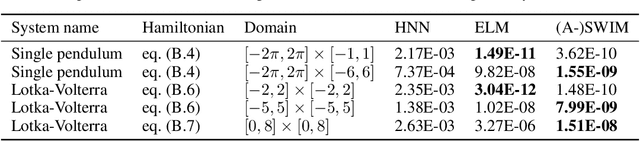

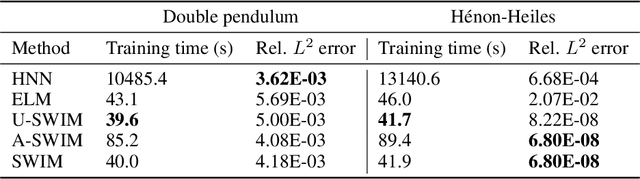
Neural networks that synergistically integrate data and physical laws offer great promise in modeling dynamical systems. However, iterative gradient-based optimization of network parameters is often computationally expensive and suffers from slow convergence. In this work, we present a backpropagation-free algorithm to accelerate the training of neural networks for approximating Hamiltonian systems through data-agnostic and data-driven algorithms. We empirically show that data-driven sampling of the network parameters outperforms data-agnostic sampling or the traditional gradient-based iterative optimization of the network parameters when approximating functions with steep gradients or wide input domains. We demonstrate that our approach is more than 100 times faster with CPUs than the traditionally trained Hamiltonian Neural Networks using gradient-based iterative optimization and is more than four orders of magnitude accurate in chaotic examples, including the H\'enon-Heiles system.
Systematic construction of continuous-time neural networks for linear dynamical systems
Mar 24, 2024Discovering a suitable neural network architecture for modeling complex dynamical systems poses a formidable challenge, often involving extensive trial and error and navigation through a high-dimensional hyper-parameter space. In this paper, we discuss a systematic approach to constructing neural architectures for modeling a subclass of dynamical systems, namely, Linear Time-Invariant (LTI) systems. We use a variant of continuous-time neural networks in which the output of each neuron evolves continuously as a solution of a first-order or second-order Ordinary Differential Equation (ODE). Instead of deriving the network architecture and parameters from data, we propose a gradient-free algorithm to compute sparse architecture and network parameters directly from the given LTI system, leveraging its properties. We bring forth a novel neural architecture paradigm featuring horizontal hidden layers and provide insights into why employing conventional neural architectures with vertical hidden layers may not be favorable. We also provide an upper bound on the numerical errors of our neural networks. Finally, we demonstrate the high accuracy of our constructed networks on three numerical examples.
Sampling weights of deep neural networks
Jun 29, 2023



We introduce a probability distribution, combined with an efficient sampling algorithm, for weights and biases of fully-connected neural networks. In a supervised learning context, no iterative optimization or gradient computations of internal network parameters are needed to obtain a trained network. The sampling is based on the idea of random feature models. However, instead of a data-agnostic distribution, e.g., a normal distribution, we use both the input and the output training data of the supervised learning problem to sample both shallow and deep networks. We prove that the sampled networks we construct are universal approximators. We also show that our sampling scheme is invariant to rigid body transformations and scaling of the input data. This implies many popular pre-processing techniques are no longer required. For Barron functions, we show that the $L^2$-approximation error of sampled shallow networks decreases with the square root of the number of neurons. In numerical experiments, we demonstrate that sampled networks achieve comparable accuracy as iteratively trained ones, but can be constructed orders of magnitude faster. Our test cases involve a classification benchmark from OpenML, sampling of neural operators to represent maps in function spaces, and transfer learning using well-known architectures.