 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Copycat Problems in Visual Imitation Learning via Residual Action Prediction
Jul 20, 2022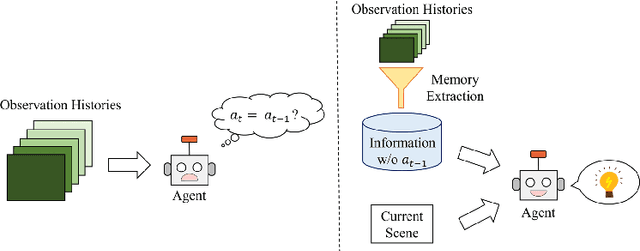

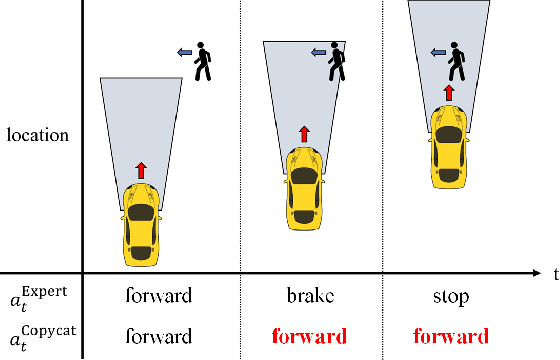

Imitation learning is a widely used policy learning method that enables intelligent agents to acquire complex skills from expert demonstrations. The input to the imitation learning algorithm is usually composed of both the current observation and historical observations since the most recent observation might not contain enough information. This is especially the case with image observations, where a single image only includes one view of the scene, and it suffers from a lack of motion information and object occlusions. In theory, providing multiple observations to the imitation learning agent will lead to better performance. However, surprisingly people find that sometimes imitation from observation histories performs worse than imitation from the most recent observation. In this paper, we explain this phenomenon from the information flow within the neural network perspective. We also propose a novel imitation learning neural network architecture that does not suffer from this issue by design. Furthermore, our method scales to high-dimensional image observations. Finally, we benchmark our approach on two widely used simulators, CARLA and MuJoCo, and it successfully alleviates the copycat problem and surpasses the existing solutions.