 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning How to Infer Partial MDPs for In-Context Adaptation and Exploration
Feb 08, 2023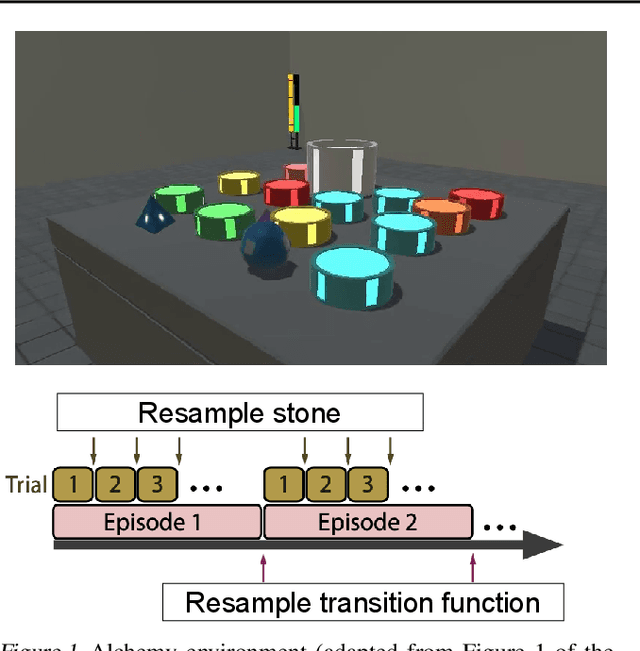
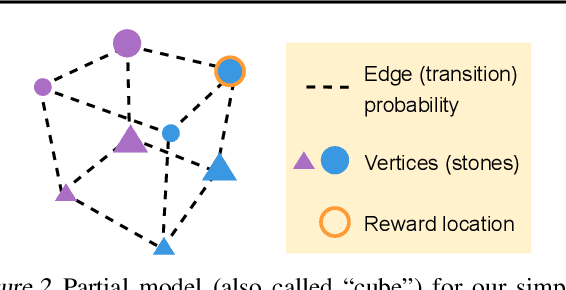
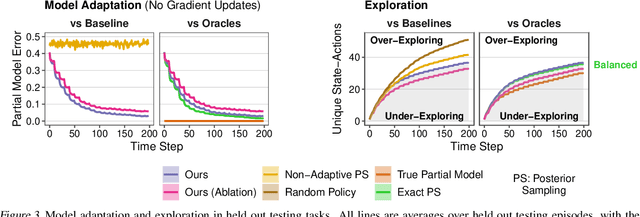
To generalize across tasks, an agent should acquire knowledge from past tasks that facilitate adaptation and exploration in future tasks. We focus on the problem of in-context adaptation and exploration, where an agent only relies on context, i.e., history of states, actions and/or rewards, rather than gradient-based updates. Posterior sampling (extension of Thompson sampling) is a promising approach, but it requires Bayesian inference and dynamic programming, which often involve unknowns (e.g., a prior) and costly computations. To address these difficulties, we use a transformer to learn an inference process from training tasks and consider a hypothesis space of partial models, represented as small Markov decision processes that are cheap for dynamic programming. In our version of the Symbolic Alchemy benchmark, our method's adaptation speed and exploration-exploitation balance approach those of an exact posterior sampling oracle. We also show that even though partial models exclude relevant information from the environment, they can nevertheless lead to good policies.
Actively learning to learn causal relationships
Jun 20, 2022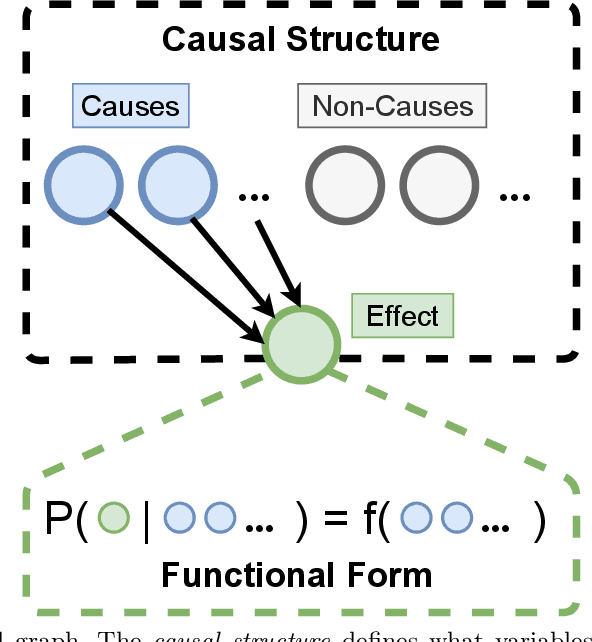
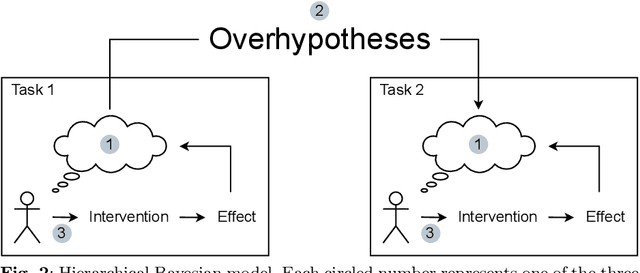
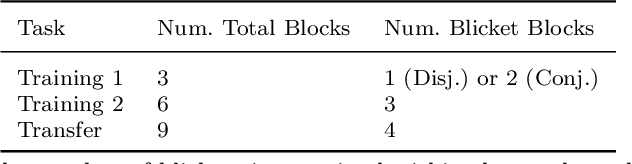
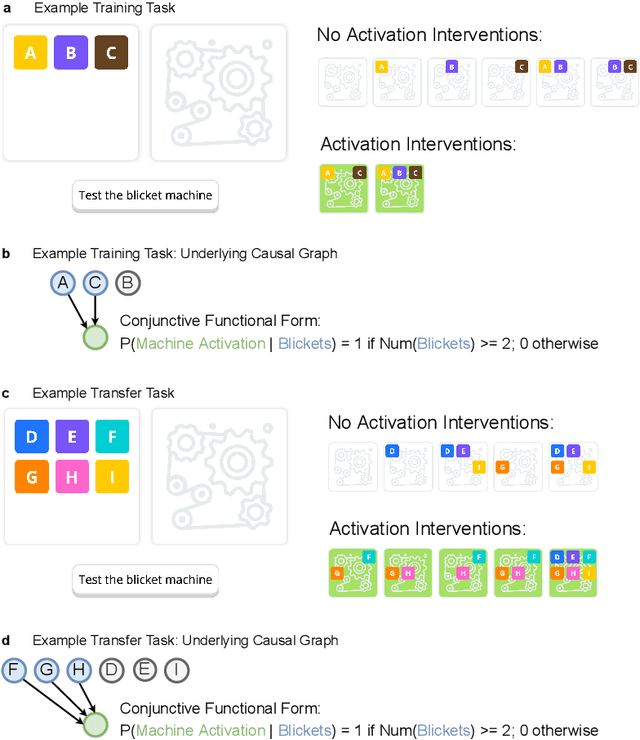
How do people actively learn to learn? That is, how and when do people choose actions that facilitate long-term learning and choosing future actions that are more informative? We explore these questions in the domain of active causal learning. We propose a hierarchical Bayesian model that goes beyond past models by predicting that people pursue information not only about the causal relationship at hand but also about causal overhypotheses$\unicode{x2014}$abstract beliefs about causal relationships that span multiple situations and constrain how we learn the specifics in each situation. In two active "blicket detector" experiments with 14 between-subjects manipulations, our model was supported by both qualitative trends in participant behavior and an individual-differences-based model comparison. Our results suggest when there are abstract similarities across active causal learning problems, people readily learn and transfer overhypotheses about these similarities. Moreover, people exploit these overhypotheses to facilitate long-term active learning.