 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSprite Sheet Diffusion: Generate Game Character for Animation
Dec 04, 2024
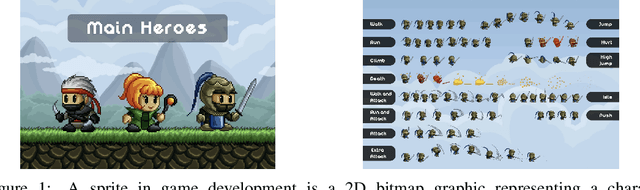

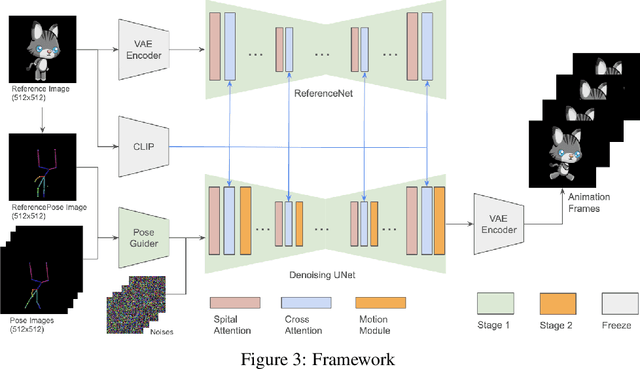
In the game development process, creating character animations is a vital step that involves several stages. Typically for 2D games, illustrators begin by designing the main character image, which serves as the foundation for all subsequent animations. To create a smooth motion sequence, these subsequent animations involve drawing the character in different poses and actions, such as running, jumping, or attacking. This process requires significant manual effort from illustrators, as they must meticulously ensure consistency in design, proportions, and style across multiple motion frames. Each frame is drawn individually, making this a time-consuming and labor-intensive task. Generative models, such as diffusion models, have the potential to revolutionize this process by automating the creation of sprite sheets. Diffusion models, known for their ability to generate diverse images, can be adapted to create character animations. By leveraging the capabilities of diffusion models, we can significantly reduce the manual workload for illustrators, accelerate the animation creation process, and open up new creative possibilities in game development.
Mr. Right: Multimodal Retrieval on Representation of ImaGe witH Text
Sep 28, 2022
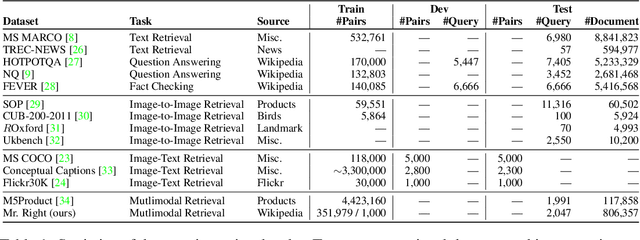
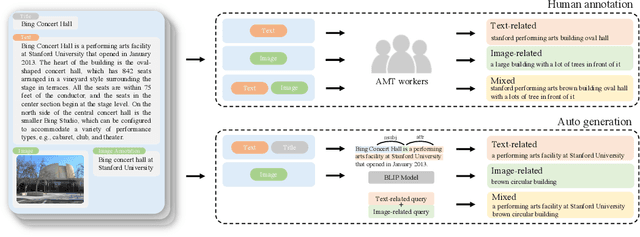
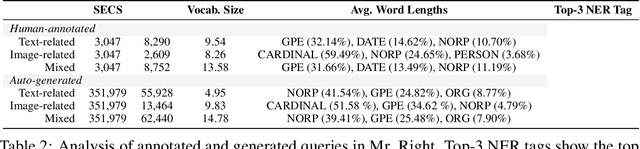
Multimodal learning is a recent challenge that extends unimodal learning by generalizing its domain to diverse modalities, such as texts, images, or speech. This extension requires models to process and relate information from multiple modalities. In Information Retrieval, traditional retrieval tasks focus on the similarity between unimodal documents and queries, while image-text retrieval hypothesizes that most texts contain the scene context from images. This separation has ignored that real-world queries may involve text content, image captions, or both. To address this, we introduce Multimodal Retrieval on Representation of ImaGe witH Text (Mr. Right), a novel and comprehensive dataset for multimodal retrieval. We utilize the Wikipedia dataset with rich text-image examples and generate three types of text-based queries with different modality information: text-related, image-related, and mixed. To validate the effectiveness of our dataset, we provide a multimodal training paradigm and evaluate previous text retrieval and image retrieval frameworks. The results show that proposed multimodal retrieval can improve retrieval performance, but creating a well-unified document representation with texts and images is still a challenge. We hope Mr. Right allows us to broaden current retrieval systems better and contributes to accelerating the advancement of multimodal learning in the Information Retrieval.