 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Adversarial Uncertainty in Evidential Deep Learning using Conflict Resolution
Jun 06, 2025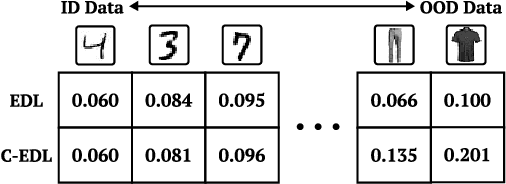
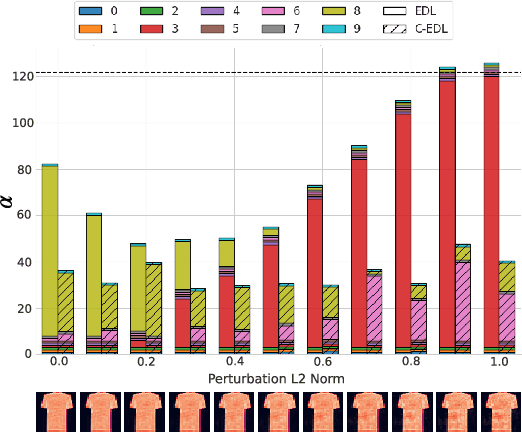


Reliability of deep learning models is critical for deployment in high-stakes applications, where out-of-distribution or adversarial inputs may lead to detrimental outcomes. Evidential Deep Learning, an efficient paradigm for uncertainty quantification, models predictions as Dirichlet distributions of a single forward pass. However, EDL is particularly vulnerable to adversarially perturbed inputs, making overconfident errors. Conflict-aware Evidential Deep Learning (C-EDL) is a lightweight post-hoc uncertainty quantification approach that mitigates these issues, enhancing adversarial and OOD robustness without retraining. C-EDL generates diverse, task-preserving transformations per input and quantifies representational disagreement to calibrate uncertainty estimates when needed. C-EDL's conflict-aware prediction adjustment improves detection of OOD and adversarial inputs, maintaining high in-distribution accuracy and low computational overhead. Our experimental evaluation shows that C-EDL significantly outperforms state-of-the-art EDL variants and competitive baselines, achieving substantial reductions in coverage for OOD data (up to 55%) and adversarial data (up to 90%), across a range of datasets, attack types, and uncertainty metrics.
Enhancing Fairness in Neural Networks Using FairVIC
Apr 28, 2024



Mitigating bias in automated decision-making systems, specifically deep learning models, is a critical challenge in achieving fairness. This complexity stems from factors such as nuanced definitions of fairness, unique biases in each dataset, and the trade-off between fairness and model accuracy. To address such issues, we introduce FairVIC, an innovative approach designed to enhance fairness in neural networks by addressing inherent biases at the training stage. FairVIC differs from traditional approaches that typically address biases at the data preprocessing stage. Instead, it integrates variance, invariance and covariance into the loss function to minimise the model's dependency on protected characteristics for making predictions, thus promoting fairness. Our experimentation and evaluation consists of training neural networks on three datasets known for their biases, comparing our results to state-of-the-art algorithms, evaluating on different sizes of model architectures, and carrying out sensitivity analysis to examine the fairness-accuracy trade-off. Through our implementation of FairVIC, we observed a significant improvement in fairness across all metrics tested, without compromising the model's accuracy to a detrimental extent. Our findings suggest that FairVIC presents a straightforward, out-of-the-box solution for the development of fairer deep learning models, thereby offering a generalisable solution applicable across many tasks and datasets.
ChatGPT as a Text Simplification Tool to Remove Bias
May 09, 2023The presence of specific linguistic signals particular to a certain sub-group of people can be picked up by language models during training. This may lead to discrimination if the model has learnt to pick up on a certain group's language. If the model begins to associate specific language with a distinct group, any decisions made based upon this language would hold a strong correlation to a decision based on their protected characteristic. We explore a possible technique for bias mitigation in the form of simplification of text. The driving force of this idea is that simplifying text should standardise language to one way of speaking while keeping the same meaning. The experiment shows promising results as the classifier accuracy for predicting the sensitive attribute drops by up to 17% for the simplified data.