 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADA: Multi-scale Collaborative Adversarial Domain Adaptation for Unsupervised Optic Disc and Cup Segmentation
Oct 05, 2021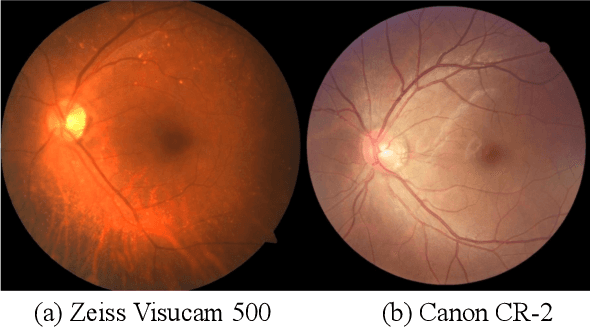

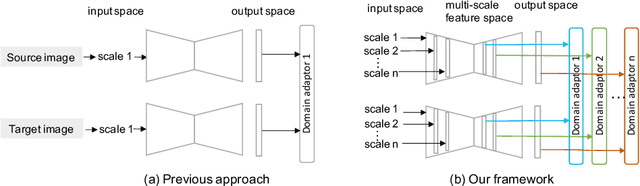
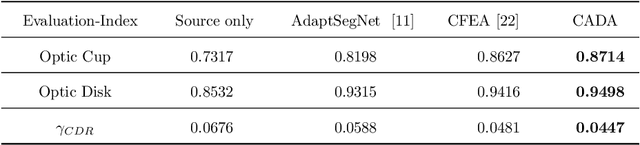
The diversity of retinal imaging devices poses a significant challenge: domain shift, which leads to performance degradation when applying the deep learning models trained on one domain to new testing domains. In this paper, we propose a multi-scale input along with multiple domain adaptors applied hierarchically in both feature and output spaces. The proposed training strategy and novel unsupervised domain adaptation framework, called Collaborative Adversarial Domain Adaptation (CADA), can effectively overcome the challenge. Multi-scale inputs can reduce the information loss due to the pooling layers used in the network for feature extraction, while our proposed CADA is an interactive paradigm that presents an exquisite collaborative adaptation through both adversarial learning and ensembling weights at different network layers. In particular, to produce a better prediction for the unlabeled target domain data, we simultaneously achieve domain invariance and model generalizability via adversarial learning at multi-scale outputs from different levels of network layers and maintaining an exponential moving average (EMA) of the historical weights during training. Without annotating any sample from the target domain, multiple adversarial losses in encoder and decoder layers guide the extraction of domain-invariant features to confuse the domain classifier. Meanwhile, the ensembling of weights via EMA reduces the uncertainty of adapting multiple discriminator learning. Comprehensive experimental results demonstrate that our CADA model incorporating multi-scale input training can overcome performance degradation and outperform state-of-the-art domain adaptation methods in segmenting retinal optic disc and cup from fundus images stemming from the REFUGE, Drishti-GS, and Rim-One-r3 datasets.