 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoRSE: Deep Learning-based Arm Gesture Recognition for Search and Rescue Operations
Oct 15, 2022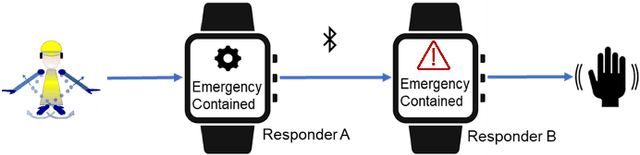
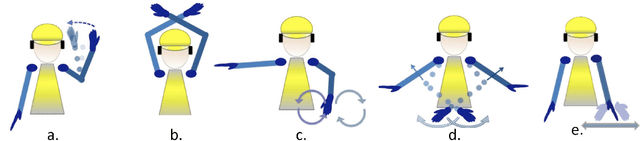

Efficient and quick remote communication in search and rescue operations can be life-saving for the first responders. However, while operating on the field means of communication based on text, image and audio are not suitable for several disaster scenarios. In this paper, we present a smartwatch-based application, which utilizes a Deep Learning (DL) model, to recognize a set of predefined arm gestures, maps them into Morse code via vibrations enabling remote communication amongst first responders. The model performance was evaluated by training it using 4,200 gestures performed by 7 subjects (cross-validation) wearing a smartwatch on their dominant arm. Our DL model relies on convolutional pooling and surpasses the performance of existing DL approaches and common machine learning classifiers, obtaining gesture recognition accuracy above 95%. We conclude by discussing the results and providing future directions.
Multi-Head Cross-Attentional PPG and Motion Signal Fusion for Heart Rate Estimation
Oct 14, 2022
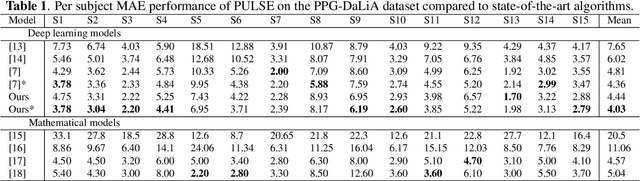
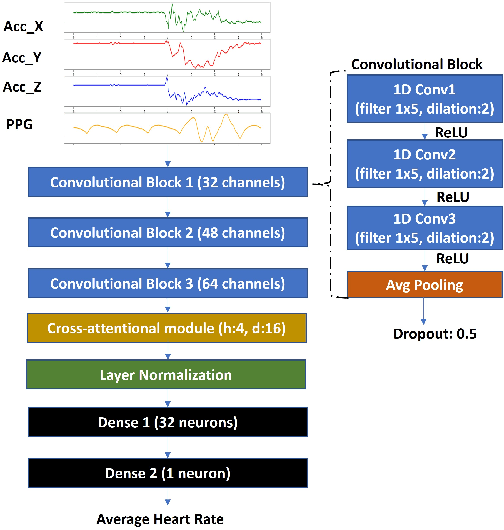
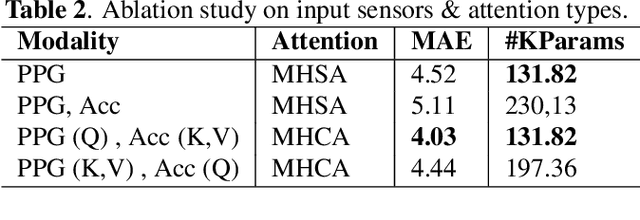
Nowadays, Hearth Rate (HR) monitoring is a key feature of almost all wrist-worn devices exploiting photoplethysmography (PPG) sensors. However, arm movements affect the performance of PPG-based HR tracking. This issue is usually addressed by fusing the PPG signal with data produced by inertial measurement units. Thus, deep learning algorithms have been proposed, but they are considered too complex to deploy on wearable devices and lack the explainability of results. In this work, we present a new deep learning model, PULSE, which exploits temporal convolutions and multi-head cross-attention to improve sensor fusion's effectiveness and achieve a step towards explainability. We evaluate the performance of PULSE on three publicly available datasets, reducing the mean absolute error by 7.56% on the most extensive available dataset, PPG-DaLiA. Finally, we demonstrate the explainability of PULSE and the benefits of applying attention modules to PPG and motion data.
PerceptionNet: A Deep Convolutional Neural Network for Late Sensor Fusion
Nov 01, 2018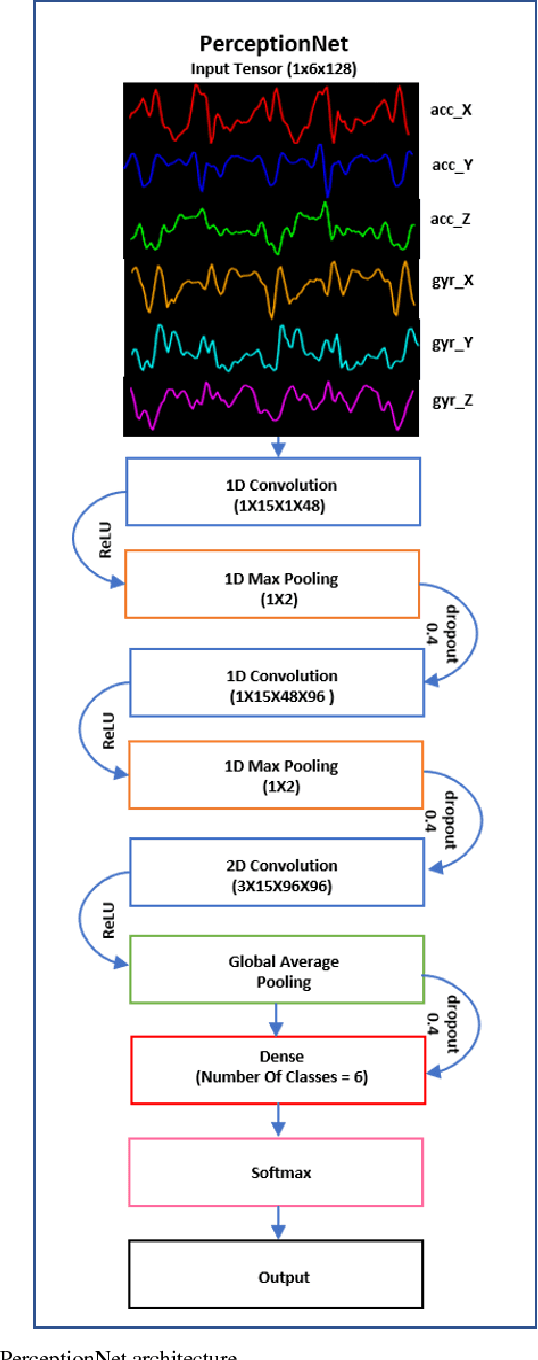
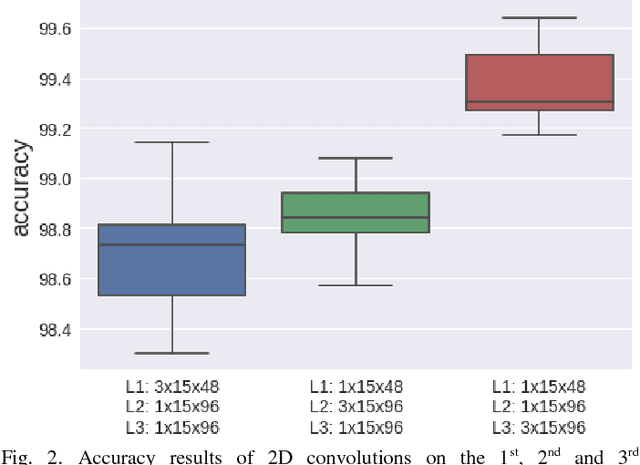
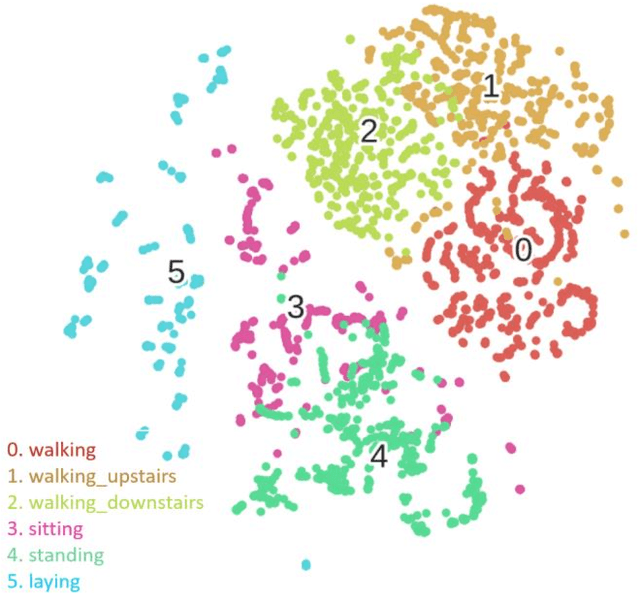
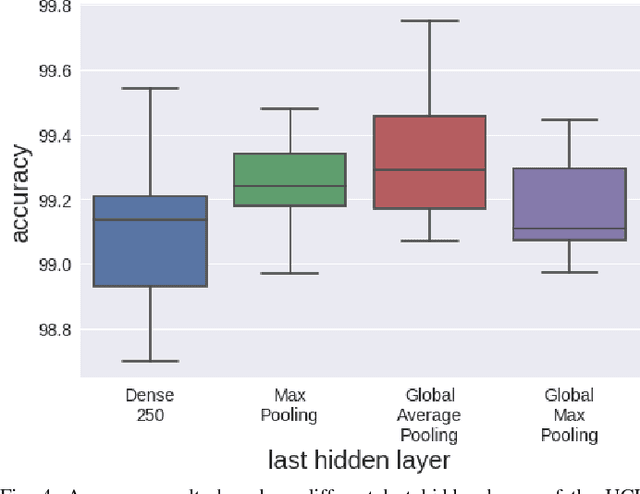
Human Activity Recognition (HAR) based on motion sensors has drawn a lot of attention over the last few years, since perceiving the human status enables context-aware applications to adapt their services on users' needs. However, motion sensor fusion and feature extraction have not reached their full potentials, remaining still an open issue. In this paper, we introduce PerceptionNet, a deep Convolutional Neural Network (CNN) that applies a late 2D convolution to multimodal time-series sensor data, in order to extract automatically efficient features for HAR. We evaluate our approach on two public available HAR datasets to demonstrate that the proposed model fuses effectively multimodal sensors and improves the performance of HAR. In particular, PerceptionNet surpasses the performance of state-of-the-art HAR methods based on: (i) features extracted from humans, (ii) deep CNNs exploiting early fusion approaches, and (iii) Long Short-Term Memory (LSTM), by an average accuracy of more than 3%.