 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Density Attention Network for Loop Filtering in Video Compression
Apr 08, 2021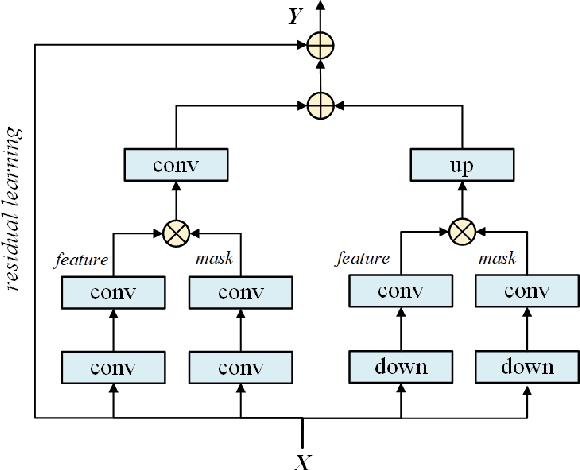


Video compression is a basic requirement for consumer and professional video applications alike. Video coding standards such as H.264/AVC and H.265/HEVC are widely deployed in the market to enable efficient use of bandwidth and storage for many video applications. To reduce the coding artifacts and improve the compression efficiency, neural network based loop filtering of the reconstructed video has been developed in the literature. However, loop filtering is a challenging task due to the variation in video content and sampling densities. In this paper, we propose a on-line scaling based multi-density attention network for loop filtering in video compression. The core of our approach lies in several aspects: (a) parallel multi-resolution convolution streams for extracting multi-density features, (b) single attention branch to learn the sample correlations and generate mask maps, (c) a channel-mutual attention procedure to fuse the data from multiple branches, (d) on-line scaling technique to further optimize the output results of network according to the actual signal. The proposed multi-density attention network learns rich features from multiple sampling densities and performs robustly on video content of different resolutions. Moreover, the online scaling process enhances the signal adaptability of the off-line pre-trained model. Experimental results show that 10.18% bit-rate reduction at the same video quality can be achieved over the latest Versatile Video Coding (VVC) standard. The objective performance of the proposed algorithm outperforms the state-of-the-art methods and the subjective quality improvement is obvious in terms of detail preservation and artifact alleviation.
A Cross Channel Context Model for Latents in Deep Image Compression
Mar 04, 2021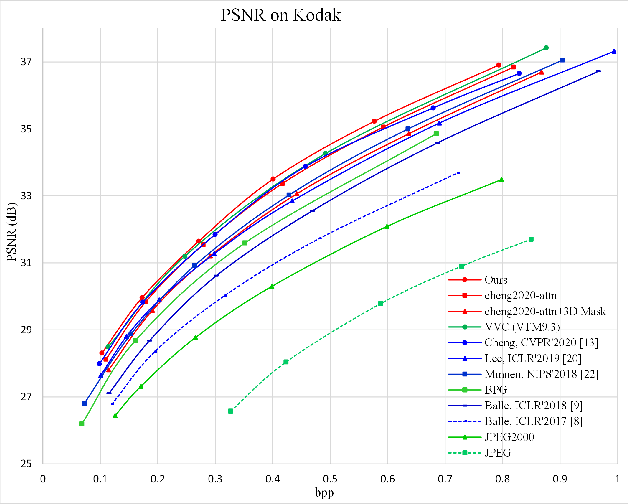
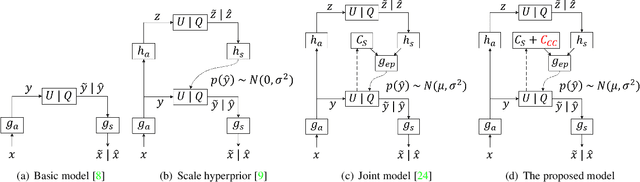
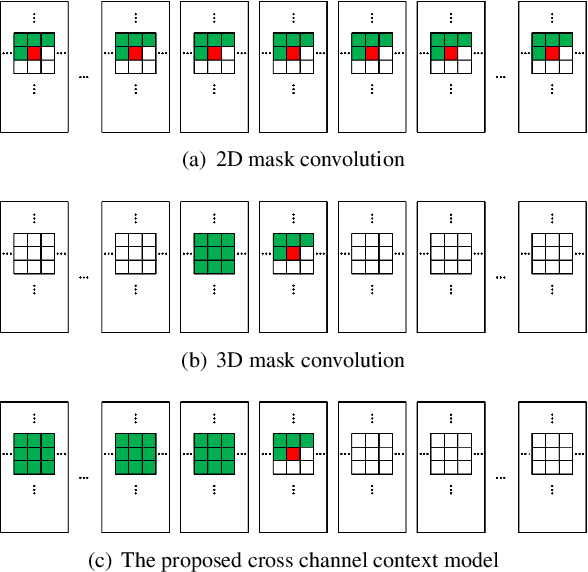
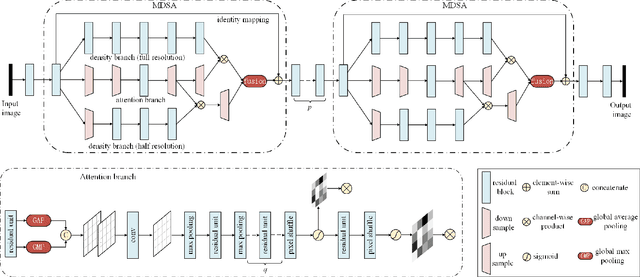
This paper presents a cross channel context model for latents in deep image compression. Generally, deep image compression is based on an autoencoder framework, which transforms the original image to latents at the encoder and recovers the reconstructed image from the quantized latents at the decoder. The transform is usually combined with an entropy model, which estimates the probability distribution of the quantized latents for arithmetic coding. Currently, joint autoregressive and hierarchical prior entropy models are widely adopted to capture both the global contexts from the hyper latents and the local contexts from the quantized latent elements. For the local contexts, the widely adopted 2D mask convolution can only capture the spatial context. However, we observe that there are strong correlations between different channels in the latents. To utilize the cross channel correlations, we propose to divide the latents into several groups according to channel index and code the groups one by one, where previously coded groups are utilized to provide cross channel context for the current group. The proposed cross channel context model is combined with the joint autoregressive and hierarchical prior entropy model. Experimental results show that, using PSNR as the distortion metric, the combined model achieves BD-rate reductions of 6.30% and 6.31% over the baseline entropy model, and 2.50% and 2.20% over the latest video coding standard Versatile Video Coding (VVC) for the Kodak and CVPR CLIC2020 professional dataset, respectively. In addition, when optimized for the MS-SSIM metric, our approach generates visually more pleasant reconstructed images.