Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaping Proto-Value Functions via Rewards
Nov 27, 2015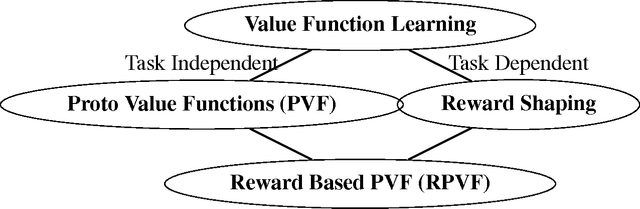

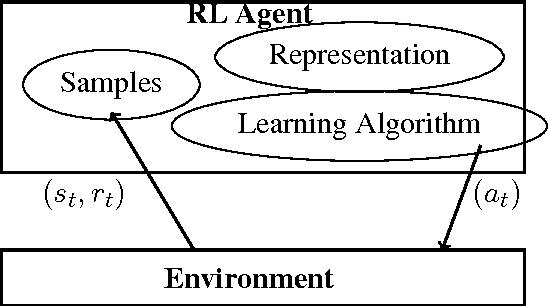
In this paper, we combine task-dependent reward shaping and task-independent proto-value functions to obtain reward dependent proto-value functions (RPVFs). In constructing the RPVFs we are making use of the immediate rewards which are available during the sampling phase but are not used in the PVF construction. We show via experiments that learning with an RPVF based representation is better than learning with just reward shaping or PVFs. In particular, when the state space is symmetrical and the rewards are asymmetrical, the RPVF capture the asymmetry better than the PVFs.
Via