 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaViTT: Random Vision Transformer Tokens
Jun 19, 2023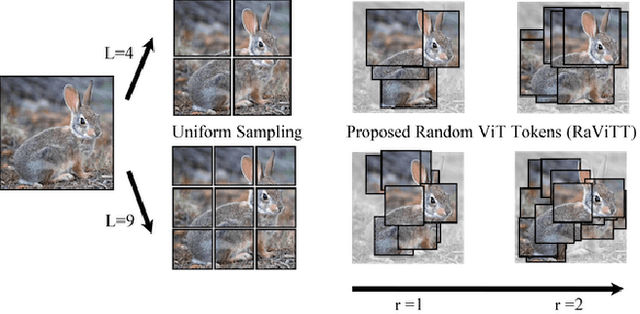
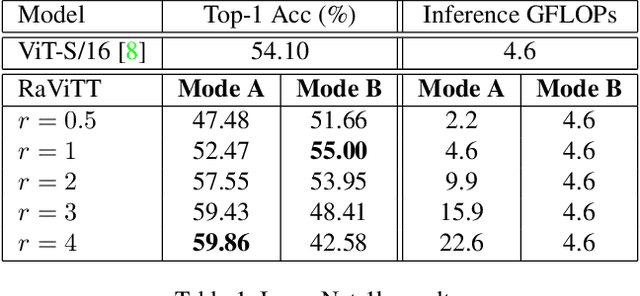
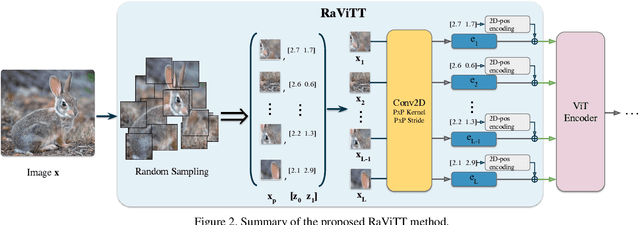
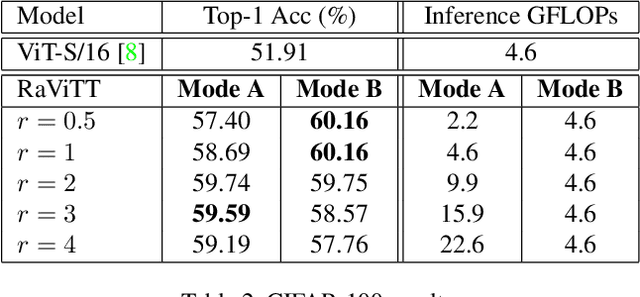
Vision Transformers (ViTs) have successfully been applied to image classification problems where large annotated datasets are available. On the other hand, when fewer annotations are available, such as in biomedical applications, image augmentation techniques like introducing image variations or combinations have been proposed. However, regarding ViT patch sampling, less has been explored outside grid-based strategies. In this work, we propose Random Vision Transformer Tokens (RaViTT), a random patch sampling strategy that can be incorporated into existing ViTs. We experimentally evaluated RaViTT for image classification, comparing it with a baseline ViT and state-of-the-art (SOTA) augmentation techniques in 4 datasets, including ImageNet-1k and CIFAR-100. Results show that RaViTT increases the accuracy of the baseline in all datasets and outperforms the SOTA augmentation techniques in 3 out of 4 datasets by a significant margin +1.23% to +4.32%. Interestingly, RaViTT accuracy improvements can be achieved even with fewer tokens, thus reducing the computational load of any ViT model for a given accuracy value.