 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised discovery of the shared and private geometry in multi-view data
Aug 22, 2024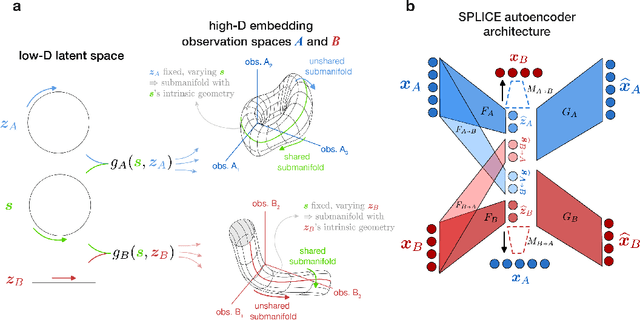
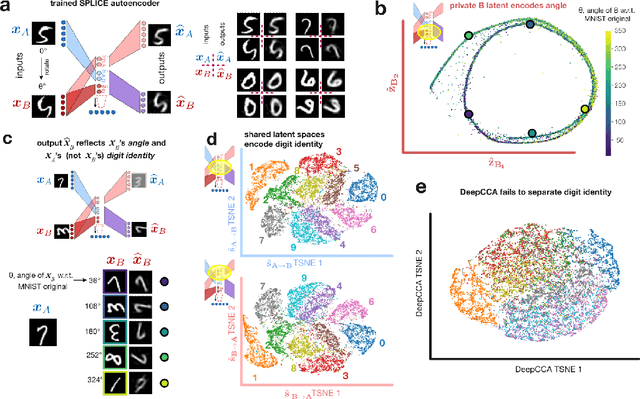
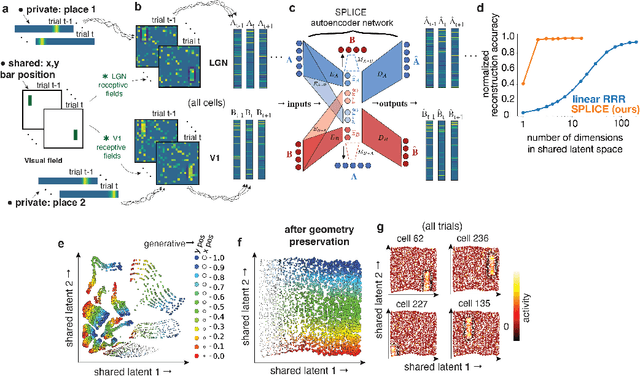
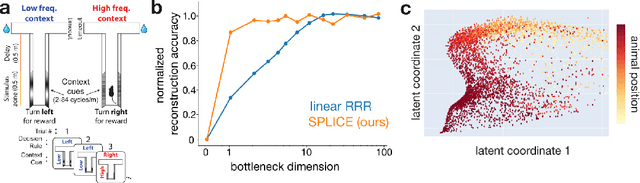
Modern applications often leverage multiple views of a subject of study. Within neuroscience, there is growing interest in large-scale simultaneous recordings across multiple brain regions. Understanding the relationship between views (e.g., the neural activity in each region recorded) can reveal fundamental principles about the characteristics of each representation and about the system. However, existing methods to characterize such relationships either lack the expressivity required to capture complex nonlinearities, describe only sources of variance that are shared between views, or discard geometric information that is crucial to interpreting the data. Here, we develop a nonlinear neural network-based method that, given paired samples of high-dimensional views, disentangles low-dimensional shared and private latent variables underlying these views while preserving intrinsic data geometry. Across multiple simulated and real datasets, we demonstrate that our method outperforms competing methods. Using simulated populations of lateral geniculate nucleus (LGN) and V1 neurons we demonstrate our model's ability to discover interpretable shared and private structure across different noise conditions. On a dataset of unrotated and corresponding but randomly rotated MNIST digits, we recover private latents for the rotated view that encode rotation angle regardless of digit class, and places the angle representation on a 1-d manifold, while shared latents encode digit class but not rotation angle. Applying our method to simultaneous Neuropixels recordings of hippocampus and prefrontal cortex while mice run on a linear track, we discover a low-dimensional shared latent space that encodes the animal's position. We propose our approach as a general-purpose method for finding succinct and interpretable descriptions of paired data sets in terms of disentangled shared and private latent variables.
Brief technical note on linearizing recurrent neural networks (RNNs) before vs after the pointwise nonlinearity
Sep 07, 2023Linearization of the dynamics of recurrent neural networks (RNNs) is often used to study their properties. The same RNN dynamics can be written in terms of the ``activations" (the net inputs to each unit, before its pointwise nonlinearity) or in terms of the ``activities" (the output of each unit, after its pointwise nonlinearity); the two corresponding linearizations are different from each other. This brief and informal technical note describes the relationship between the two linearizations, between the left and right eigenvectors of their dynamics matrices, and shows that some context-dependent effects are readily apparent under linearization of activity dynamics but not linearization of activation dynamics.
Limitations of a proposed correction for slow drifts in decision criterion
May 22, 2022Trial history biases in decision-making tasks are thought to reflect systematic updates of decision variables, therefore their precise nature informs conclusions about underlying heuristic strategies and learning processes. However, random drifts in decision variables can corrupt this inference by mimicking the signatures of systematic updates. Hence, identifying the trial-by-trial evolution of decision variables requires methods that can robustly account for such drifts. Recent studies (Lak'20, Mendon\c{c}a'20) have made important advances in this direction, by proposing a convenient method to correct for the influence of slow drifts in decision criterion, a key decision variable. Here we apply this correction to a variety of updating scenarios, and evaluate its performance. We show that the correction fails for a wide range of commonly assumed systematic updating strategies, distorting one's inference away from the veridical strategies towards a narrow subset. To address these limitations, we propose a model-based approach for disambiguating systematic updates from random drifts, and demonstrate its success on real and synthetic datasets. We show that this approach accurately recovers the latent trajectory of drifts in decision criterion as well as the generative systematic updates from simulated data. Our results offer recommendations for methods to account for the interactions between history biases and slow drifts, and highlight the advantages of incorporating assumptions about the generative process directly into models of decision-making.