 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural posterior estimation of the neutrino direction in IceCube using transformer-encoded normalizing flows on the sphere
Apr 21, 2026IceCube is a cubic-kilometer-scale neutrino detector located at the geographic South Pole. A precise directional reconstruction of IceCube neutrinos is vital for associations with astronomical objects. In this context, we discuss neural posterior estimation of the neutrino direction via a transformer encoder that maps to a normalizing flow on the 2-sphere. It achieves a new state-of-the-art angular resolution for the two main event morphologies in IceCube - tracks and showers - while being significantly faster than traditional B-spline-based likelihood reconstructions. All-sky scans can be performed within seconds rather than hours, and take constant computation time, regardless of whether the posterior extent is arc-minutes or spans the whole sky. We utilize a combination of $C^2$-smooth rational-quadratic splines, scale transformations and rotations to define a novel spherical normalizing-flow distribution whose parameters are predicted as a whole as the output of the transformer encoder. We test several structural choices diverting from the vanilla transformer architecture. In particular, we find dual residual streams, nonlinear QKV projection and a separate class token with its own cross-attention processing to boost test-time performance. The angular resolution for both showers and tracks improves substantially over the whole trained energy range from 100 GeV to 100 PeV. At 100 TeV deposited energy, for example, the median angular resolution improves by a factor of $1.3$ for throughgoing tracks, by a factor of $1.7$ for showers and by a factor of $2.5$ for starting tracks compared to state-of-the art likelihood reconstructions based on B-splines. While previous machine-learning (ML) efforts have managed to obtain competitive shower resolutions, this is the first time an ML-based method outperforms likelihood-based muon reconstructions above 100 GeV.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
On Minimum Trace Factor Analysis -- An Old Song Sung to a New Tune
Feb 04, 2024



Dimensionality reduction methods, such as principal component analysis (PCA) and factor analysis, are central to many problems in data science. There are, however, serious and well-understood challenges to finding robust low dimensional approximations for data with significant heteroskedastic noise. This paper introduces a relaxed version of Minimum Trace Factor Analysis (MTFA), a convex optimization method with roots dating back to the work of Ledermann in 1940. This relaxation is particularly effective at not overfitting to heteroskedastic perturbations and addresses the commonly cited Heywood cases in factor analysis and the recently identified "curse of ill-conditioning" for existing spectral methods. We provide theoretical guarantees on the accuracy of the resulting low rank subspace and the convergence rate of the proposed algorithm to compute that matrix. We develop a number of interesting connections to existing methods, including HeteroPCA, Lasso, and Soft-Impute, to fill an important gap in the already large literature on low rank matrix estimation. Numerical experiments benchmark our results against several recent proposals for dealing with heteroskedastic noise.
CH-Go: Online Go System Based on Chunk Data Storage
Mar 22, 2023



The training and running of an online Go system require the support of effective data management systems to deal with vast data, such as the initial Go game records, the feature data set obtained by representation learning, the experience data set of self-play, the randomly sampled Monte Carlo tree, and so on. Previous work has rarely mentioned this problem, but the ability and efficiency of data management systems determine the accuracy and speed of the Go system. To tackle this issue, we propose an online Go game system based on the chunk data storage method (CH-Go), which processes the format of 160k Go game data released by Kiseido Go Server (KGS) and designs a Go encoder with 11 planes, a parallel processor and generator for better memory performance. Specifically, we store the data in chunks, take the chunk size of 1024 as a batch, and save the features and labels of each chunk as binary files. Then a small set of data is randomly sampled each time for the neural network training, which is accessed by batch through yield method. The training part of the prototype includes three modules: supervised learning module, reinforcement learning module, and an online module. Firstly, we apply Zobrist-guided hash coding to speed up the Go board construction. Then we train a supervised learning policy network to initialize the self-play for generation of experience data with 160k Go game data released by KGS. Finally, we conduct reinforcement learning based on REINFORCE algorithm. Experiments show that the training accuracy of CH- Go in the sampled 150 games is 99.14%, and the accuracy in the test set is as high as 98.82%. Under the condition of limited local computing power and time, we have achieved a better level of intelligence. Given the current situation that classical systems such as GOLAXY are not free and open, CH-Go has realized and maintained complete Internet openness.
A Unifying Framework for Formal Theories of Novelty:Framework, Examples and Discussion
Dec 08, 2020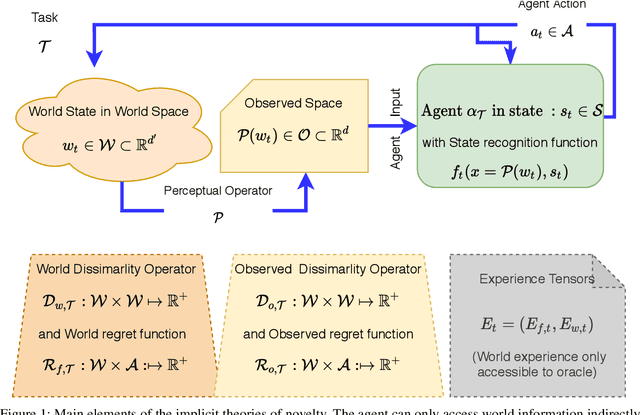


Managing inputs that are novel, unknown, or out-of-distribution is critical as an agent moves from the lab to the open world. Novelty-related problems include being tolerant to novel perturbations of the normal input, detecting when the input includes novel items, and adapting to novel inputs. While significant research has been undertaken in these areas, a noticeable gap exists in the lack of a formalized definition of novelty that transcends problem domains. As a team of researchers spanning multiple research groups and different domains, we have seen, first hand, the difficulties that arise from ill-specified novelty problems, as well as inconsistent definitions and terminology. Therefore, we present the first unified framework for formal theories of novelty and use the framework to formally define a family of novelty types. Our framework can be applied across a wide range of domains, from symbolic AI to reinforcement learning, and beyond to open world image recognition. Thus, it can be used to help kick-start new research efforts and accelerate ongoing work on these important novelty-related problems. This extended version of our AAAI 2021 paper included more details and examples in multiple domains.