 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultivariate Dependency Measure based on Copula and Gaussian Kernel
Jan 10, 2018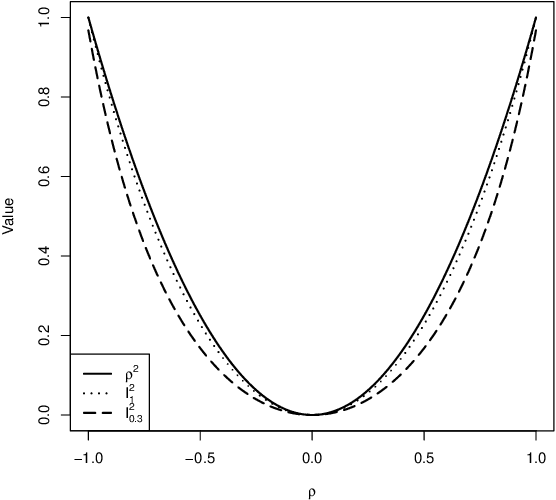
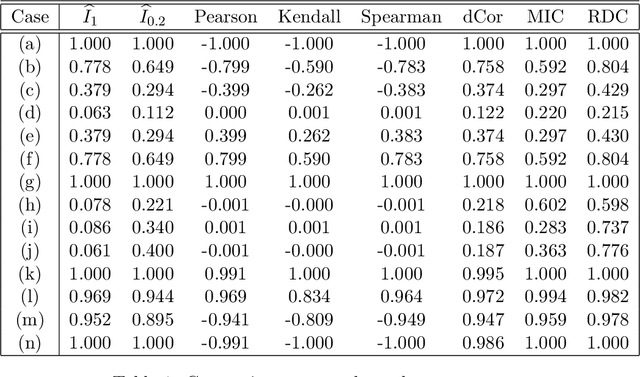
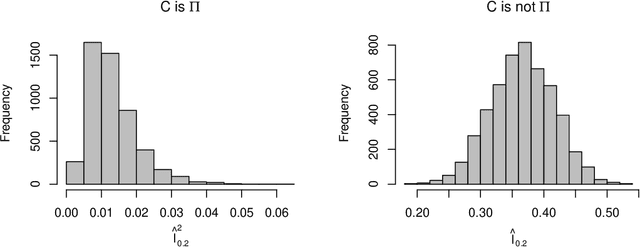
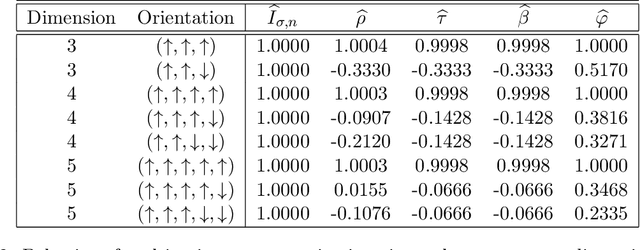
We propose a new multivariate dependency measure. It is obtained by considering a Gaussian kernel based distance between the copula transform of the given d-dimensional distribution and the uniform copula and then appropriately normalizing it. The resulting measure is shown to satisfy a number of desirable properties. A nonparametric estimate is proposed for this dependency measure and its properties (finite sample as well as asymptotic) are derived. Some comparative studies of the proposed dependency measure estimate with some widely used dependency measure estimates on artificial datasets are included. A non-parametric test of independence between two or more random variables based on this measure is proposed. A comparison of the proposed test with some existing nonparametric multivariate test for independence is presented.
A new estimate of mutual information based measure of dependence between two variables: properties and fast implementation
Sep 14, 2015
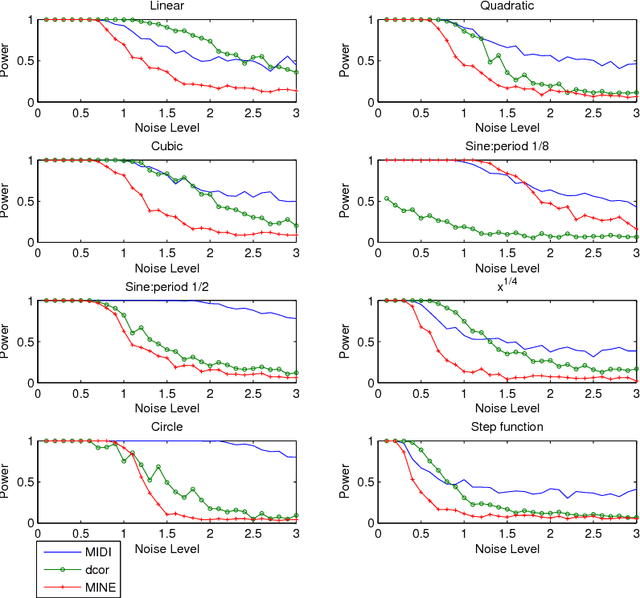
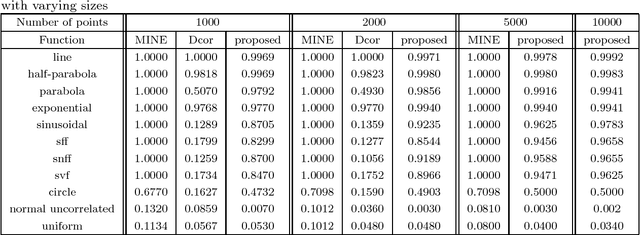
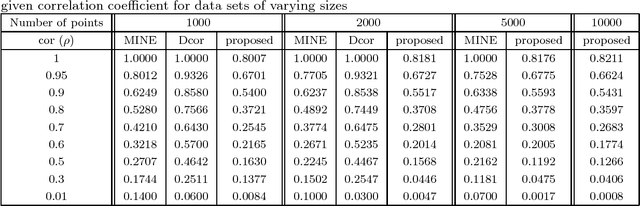
This article proposes a new method to estimate an existing mutual information based dependence measure using histogram density estimates. Finding a suitable bin length for histogram is an open problem. We propose a new way of computing the bin length for histogram using a function of maximum separation between points. The chosen bin length leads to consistent density estimates for histogram method. The values of density thus obtained are used to calculate an estimate of an existing dependence measure. The proposed estimate is named as Mutual Information Based Dependence Index (MIDI). Some important properties of MIDI have also been stated. The performance of the proposed method has been compared to generally accepted measures like Distance Correlation (dcor), Maximal Information Coefficient (MINE) in terms of accuracy and computational complexity with the help of several artificial data sets with different amounts of noise. The proposed method is able to detect many types of relationships between variables, without making any assumption about the functional form of the relationship. The power statistics of proposed method illustrate their effectiveness in detecting non linear relationship. Thus, it is able to achieve generality without a high rate of false positive cases. MIDI is found to work better on a real life data set than competing methods. The proposed method is found to overcome some of the limitations which occur with dcor and MINE. Computationally, MIDI is found to be better than dcor and MINE, in terms of time and memory, making it suitable for large data sets.