 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment and stability of embeddings: measurement and inference improvement
Jan 18, 2021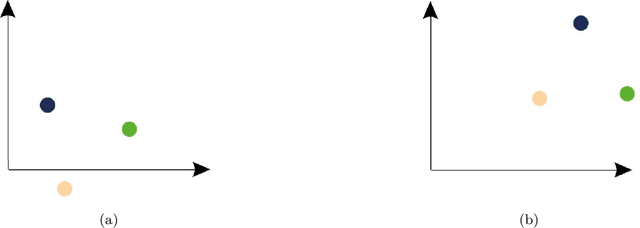
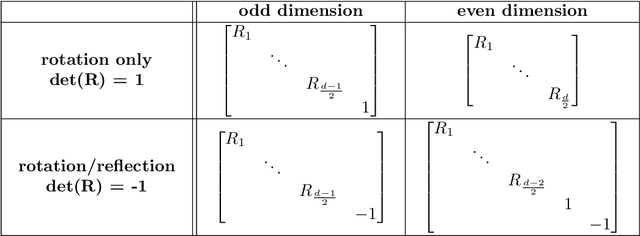
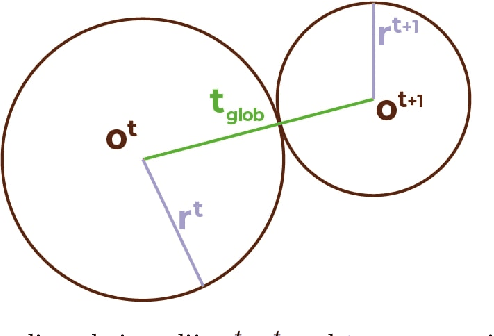

Representation learning (RL) methods learn objects' latent embeddings where information is preserved by distances. Since distances are invariant to certain linear transformations, one may obtain different embeddings while preserving the same information. In dynamic systems, a temporal difference in embeddings may be explained by the stability of the system or by the misalignment of embeddings due to arbitrary transformations. In the literature, embedding alignment has not been defined formally, explored theoretically, or analyzed empirically. Here, we explore the embedding alignment and its parts, provide the first formal definitions, propose novel metrics to measure alignment and stability, and show their suitability through synthetic experiments. Real-world experiments show that both static and dynamic RL methods are prone to produce misaligned embeddings and such misalignment worsens the performance of dynamic network inference tasks. By ensuring alignment, the prediction accuracy raises by up to 90% in static and by 40% in dynamic RL methods.
Community structure: A comparative evaluation of community detection methods
Jan 07, 2019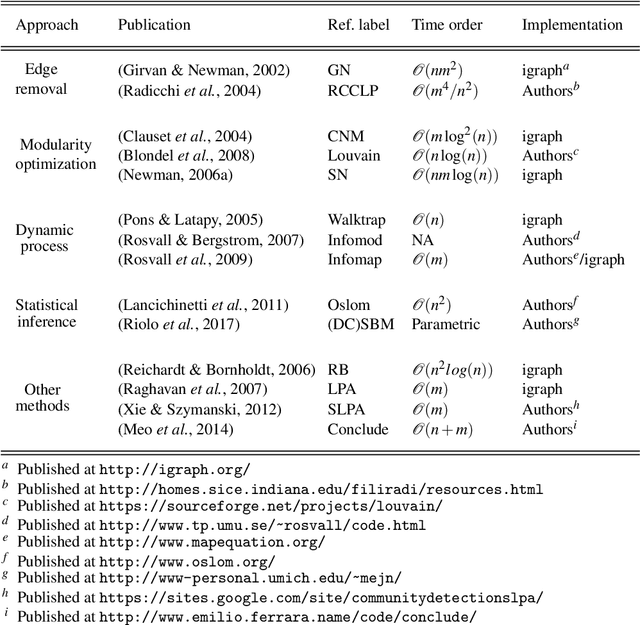
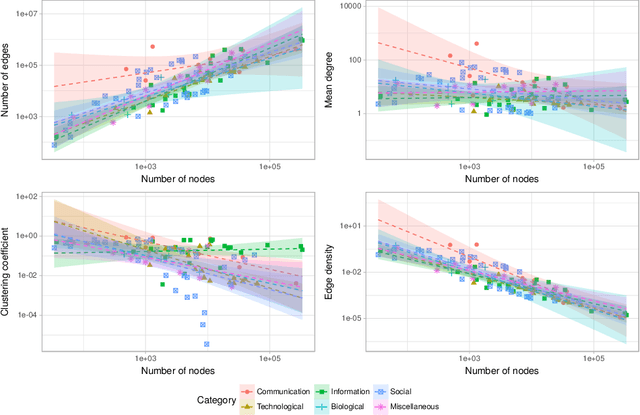
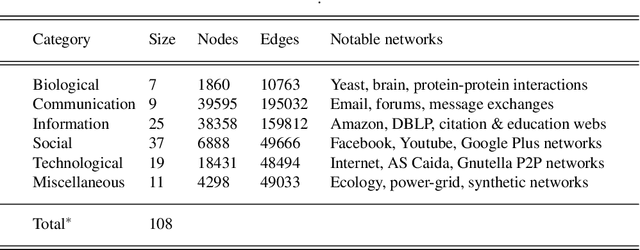
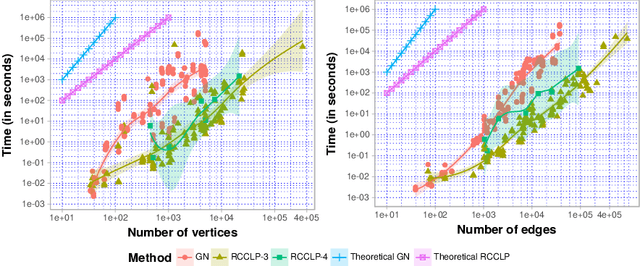
Discovering community structure in complex networks is a mature field since a tremendous number of community detection methods have been introduced in the literature. Nevertheless, it is still very challenging for practioners to determine which method would be suitable to get insights into the structural information of the networks they study. Many recent efforts have been devoted to investigating various quality scores of the community structure, but the problem of distinguishing between different types of communities is still open. In this paper, we propose a comparative, extensive and empirical study to investigate what types of communities many state-of-the-art and well-known community detection methods are producing. Specifically, we provide comprehensive analyses on computation time, community size distribution, a comparative evaluation of methods according to their optimisation schemes as well as a comparison of their partioning strategy through validation metrics. We process our analyses on a very large corpus of hundreds of networks from five different network categories and propose ways to classify community detection methods, helping a potential user to navigate the complex landscape of community detection.