 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML KPI Prediction in 5G and B5G Networks
Apr 01, 2024Network operators are facing new challenges when meeting the needs of their customers. The challenges arise due to the rise of new services, such as HD video streaming, IoT, autonomous driving, etc., and the exponential growth of network traffic. In this context, 5G and B5G networks have been evolving to accommodate a wide range of applications and use cases. Additionally, this evolution brings new features, like the ability to create multiple end-to-end isolated virtual networks using network slicing. Nevertheless, to ensure the quality of service, operators must maintain and optimize their networks in accordance with the key performance indicators (KPIs) and the slice service-level agreements (SLAs). In this paper, we introduce a machine learning (ML) model used to estimate throughput in 5G and B5G networks with end-to-end (E2E) network slices. Then, we combine the predicted throughput with the current network state to derive an estimate of other network KPIs, which can be used to further improve service assurance. To assess the efficiency of our solution, a performance metric was proposed. Numerical evaluations demonstrate that our KPI prediction model outperforms those derived from other methods with the same or nearly the same computational time.
Classification of Anomalies in Telecommunication Network KPI Time Series
Aug 30, 2023

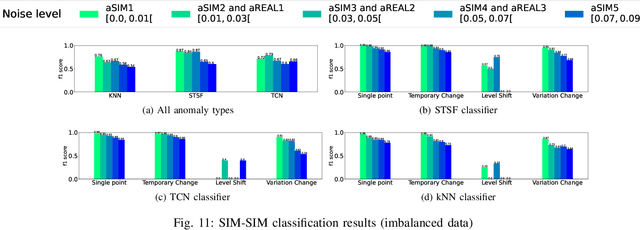

The increasing complexity and scale of telecommunication networks have led to a growing interest in automated anomaly detection systems. However, the classification of anomalies detected on network Key Performance Indicators (KPI) has received less attention, resulting in a lack of information about anomaly characteristics and classification processes. To address this gap, this paper proposes a modular anomaly classification framework. The framework assumes separate entities for the anomaly classifier and the detector, allowing for a distinct treatment of anomaly detection and classification tasks on time series. The objectives of this study are (1) to develop a time series simulator that generates synthetic time series resembling real-world network KPI behavior, (2) to build a detection model to identify anomalies in the time series, (3) to build classification models that accurately categorize detected anomalies into predefined classes (4) to evaluate the classification framework performance on simulated and real-world network KPI time series. This study has demonstrated the good performance of the anomaly classification models trained on simulated anomalies when applied to real-world network time series data.
Can we Estimate Truck Accident Risk from Telemetric Data using Machine Learning?
Jul 17, 2020
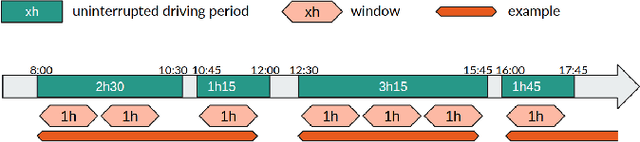


Road accidents have a high societal cost that could be reduced through improved risk predictions using machine learning. This study investigates whether telemetric data collected on long-distance trucks can be used to predict the risk of accidents associated with a driver. We use a dataset provided by a truck transportation company containing the driving data of 1,141 drivers for 18 months. We evaluate two different machine learning approaches to perform this task. In the first approach, features are extracted from the time series data using the FRESH algorithm and then used to estimate the risk using Random Forests. In the second approach, we use a convolutional neural network to directly estimate the risk from the time-series data. We find that neither approach is able to successfully estimate the risk of accidents on this dataset, in spite of many methodological attempts. We discuss the difficulties of using telemetric data for the estimation of the risk of accidents that could explain this negative result.
High-Resolution Road Vehicle Collision Prediction for the City of Montreal
May 21, 2019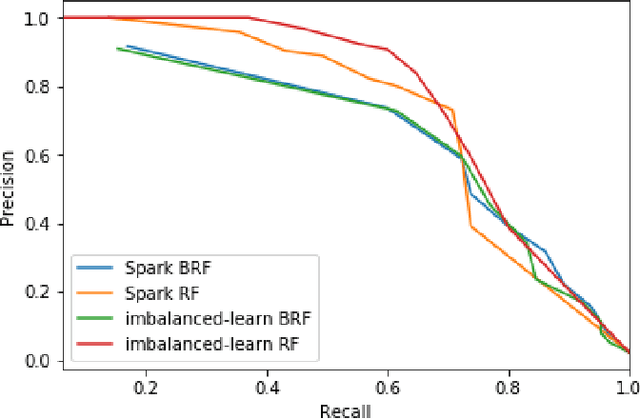
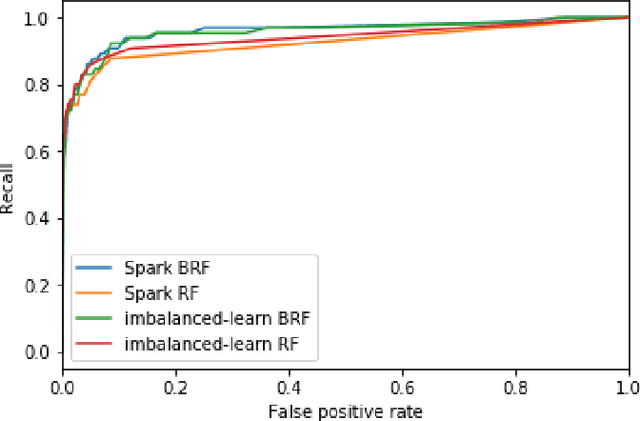
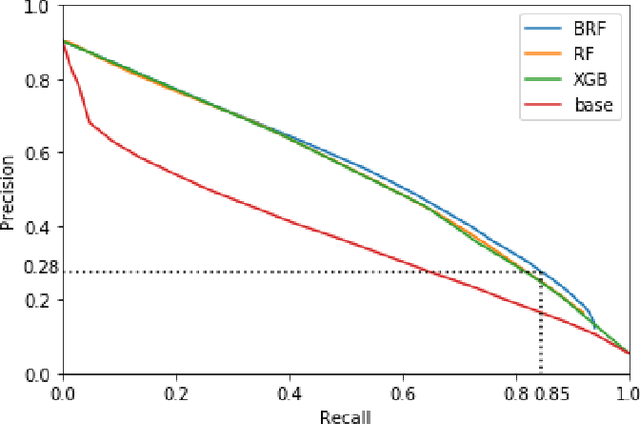

Road accidents are an important issue of our modern societies, responsible for millions of deaths and injuries every year in the world. In Quebec only, road accidents are responsible for hundreds of deaths and tens of thousands of injuries. In this paper, we show how one can leverage open datasets of a city like Montreal, Canada, to create high-resolution accident prediction models, using state-of-the-art big data analytics. Compared to other studies in road accident prediction, we have a much higher prediction resolution, i.e., our models predict the occurrence of an accident within an hour, on road segments defined by intersections. Such models could be used in the context of road accident prevention, but also to identify key factors that can lead to a road accident, and consequently, help elaborate new policies. We tested various machine learning methods to deal with the severe class imbalance inherent to accident prediction problems. In particular, we implemented the Balanced Random Forest algorithm, a variant of the Random Forest machine learning algorithm in Apache Spark. Experimental results show that 85% of road vehicle collisions are detected by our model with a false positive rate of 13%. The examples identified as positive are likely to correspond to high-risk situations. In addition, we identify the most important predictors of vehicle collisions for the area of Montreal: the count of accidents on the same road segment during previous years, the temperature, the day of the year, the hour and the visibility.
Data models for service failure prediction in supply-chain networks
Oct 20, 2018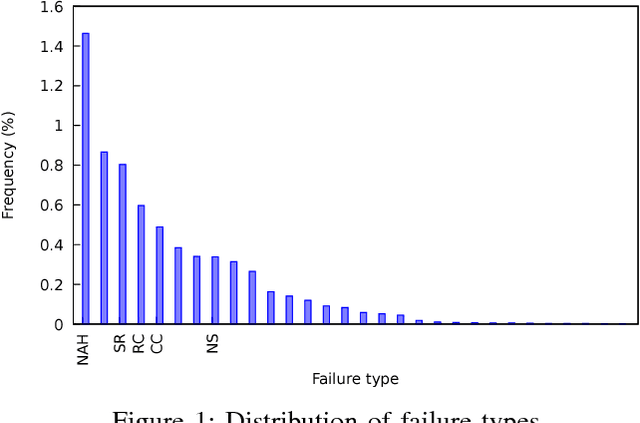
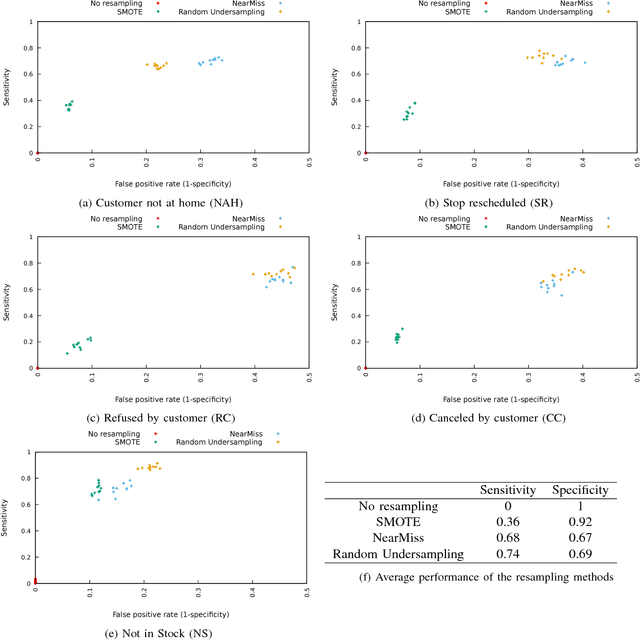
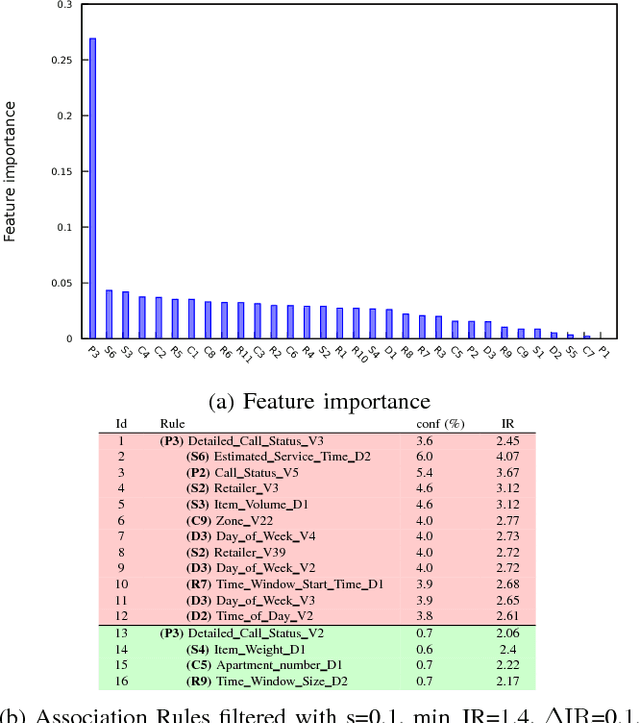
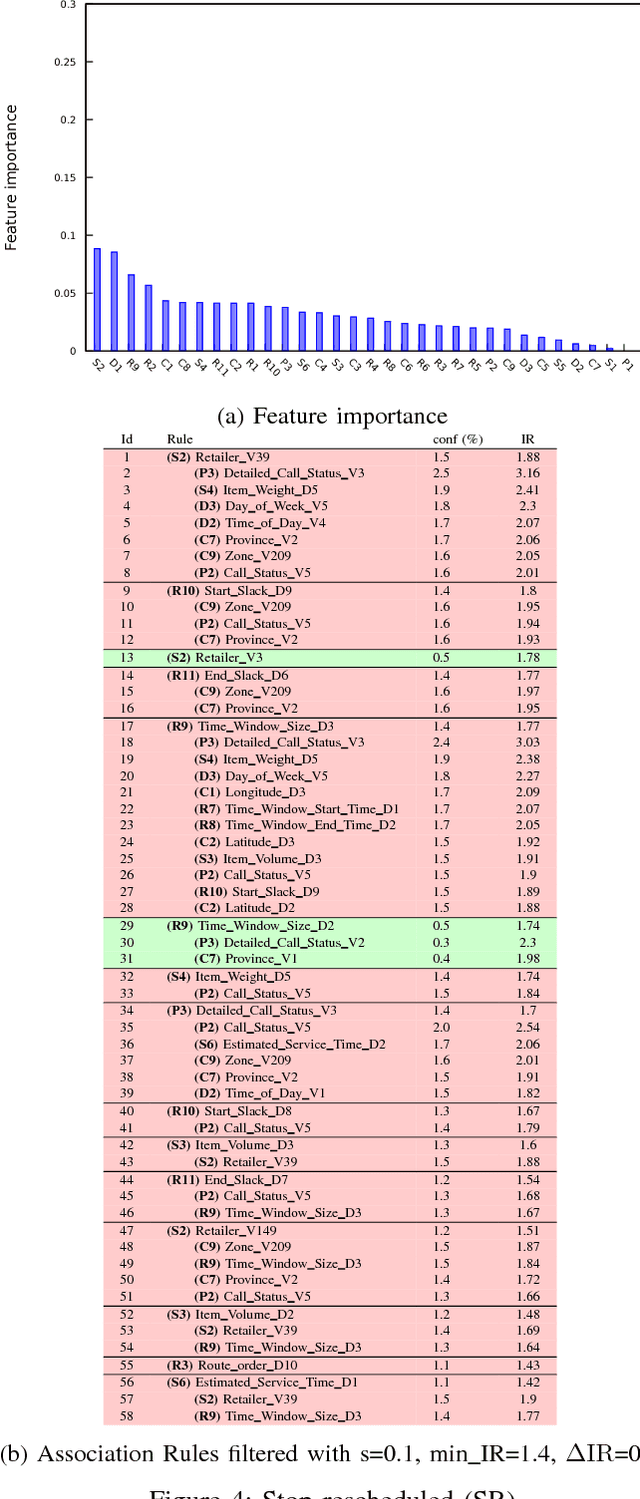
We aim to predict and explain service failures in supply-chain networks, more precisely among last-mile pickup and delivery services to customers. We analyze a dataset of 500,000 services using (1) supervised classification with Random Forests, and (2) Association Rules. Our classifier reaches an average sensitivity of 0.7 and an average specificity of 0.7 for the 5 studied types of failure. Association Rules reassert the importance of confirmation calls to prevent failures due to customers not at home, show the importance of the time window size, slack time, and geographical location of the customer for the other failure types, and highlight the effect of the retailer company on several failure types. To reduce the occurrence of service failures, our data models could be coupled to optimizers, or used to define counter-measures to be taken by human dispatchers.