 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Tricks for Natural Policy Gradient Reinforcement Learning
Jan 22, 2022
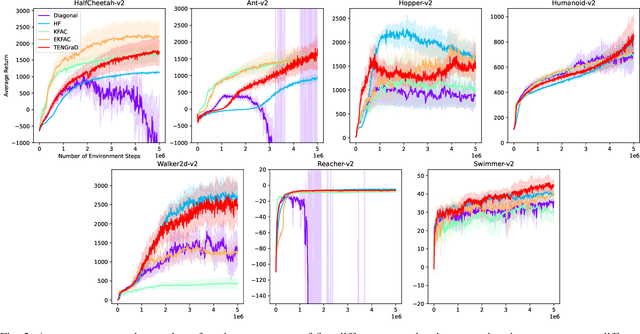

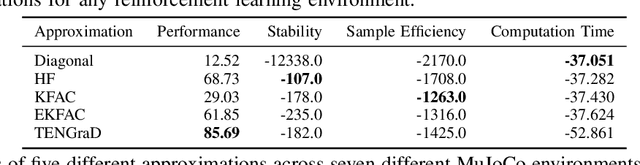
Natural policy gradient methods are popular reinforcement learning methods that improve the stability of policy gradient methods by preconditioning the gradient with the inverse of the Fisher-information matrix. However, leveraging natural policy gradient methods in an optimal manner can be very challenging as many implementation details must be set to achieve optimal performance. To the best of the authors' knowledge, there has not been a study that has investigated strategies for setting these details for natural policy gradient methods to achieve high performance in a comprehensive and systematic manner. To address this, we have implemented and compared strategies that impact performance in natural policy gradient reinforcement learning across five different second-order approximations. These include varying batch sizes and optimizing the critic network using the natural gradient. Furthermore, insights about the fundamental trade-offs when optimizing for performance (stability, sample efficiency, and computation time) were generated. Experimental results indicate that the proposed collection of strategies for performance optimization can improve results by 86% to 181% across the MuJuCo control benchmark, with TENGraD exhibiting the best approximation performance amongst the tested approximations. Code in this study is available at https://github.com/gebob19/natural-policy-gradient-reinforcement-learning.
M2A: Motion Aware Attention for Accurate Video Action Recognition
Nov 18, 2021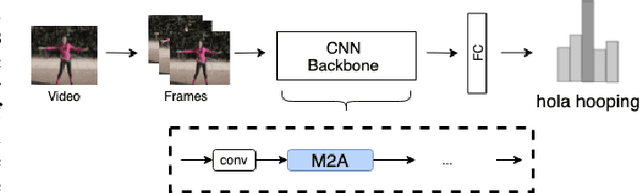
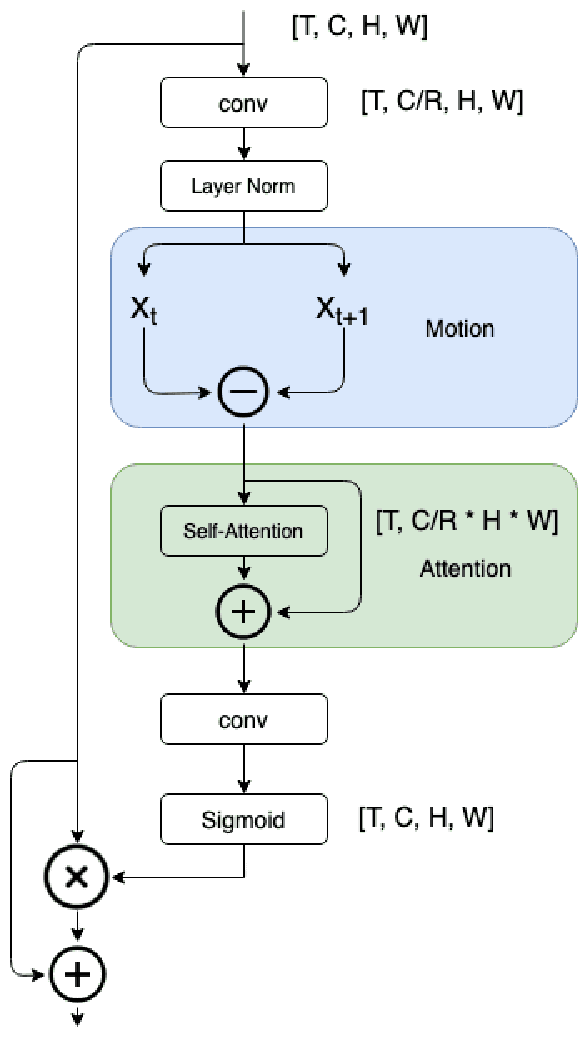


Advancements in attention mechanisms have led to significant performance improvements in a variety of areas in machine learning due to its ability to enable the dynamic modeling of temporal sequences. A particular area in computer vision that is likely to benefit greatly from the incorporation of attention mechanisms in video action recognition. However, much of the current research's focus on attention mechanisms have been on spatial and temporal attention, which are unable to take advantage of the inherent motion found in videos. Motivated by this, we develop a new attention mechanism called Motion Aware Attention (M2A) that explicitly incorporates motion characteristics. More specifically, M2A extracts motion information between consecutive frames and utilizes attention to focus on the motion patterns found across frames to accurately recognize actions in videos. The proposed M2A mechanism is simple to implement and can be easily incorporated into any neural network backbone architecture. We show that incorporating motion mechanisms with attention mechanisms using the proposed M2A mechanism can lead to a +15% to +26% improvement in top-1 accuracy across different backbone architectures, with only a small increase in computational complexity. We further compared the performance of M2A with other state-of-the-art motion and attention mechanisms on the Something-Something V1 video action recognition benchmark. Experimental results showed that M2A can lead to further improvements when combined with other temporal mechanisms and that it outperforms other motion-only or attention-only mechanisms by as much as +60% in top-1 accuracy for specific classes in the benchmark.