 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Tricks for Natural Policy Gradient Reinforcement Learning
Paper and Code
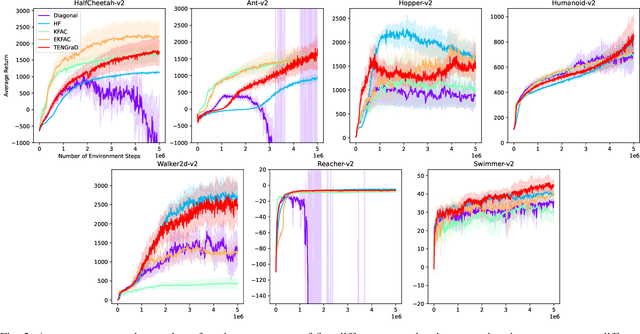

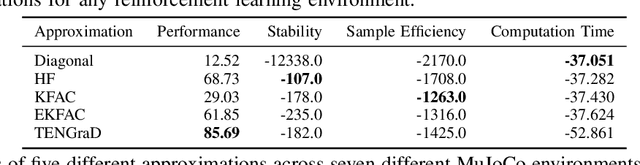
Natural policy gradient methods are popular reinforcement learning methods that improve the stability of policy gradient methods by preconditioning the gradient with the inverse of the Fisher-information matrix. However, leveraging natural policy gradient methods in an optimal manner can be very challenging as many implementation details must be set to achieve optimal performance. To the best of the authors' knowledge, there has not been a study that has investigated strategies for setting these details for natural policy gradient methods to achieve high performance in a comprehensive and systematic manner. To address this, we have implemented and compared strategies that impact performance in natural policy gradient reinforcement learning across five different second-order approximations. These include varying batch sizes and optimizing the critic network using the natural gradient. Furthermore, insights about the fundamental trade-offs when optimizing for performance (stability, sample efficiency, and computation time) were generated. Experimental results indicate that the proposed collection of strategies for performance optimization can improve results by 86% to 181% across the MuJuCo control benchmark, with TENGraD exhibiting the best approximation performance amongst the tested approximations. Code in this study is available at https://github.com/gebob19/natural-policy-gradient-reinforcement-learning.