 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-On-Policy Training for Sample Efficient Multi-Agent Policy Gradients
May 06, 2021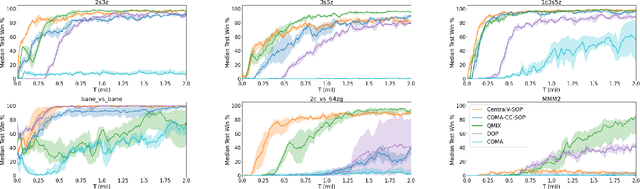
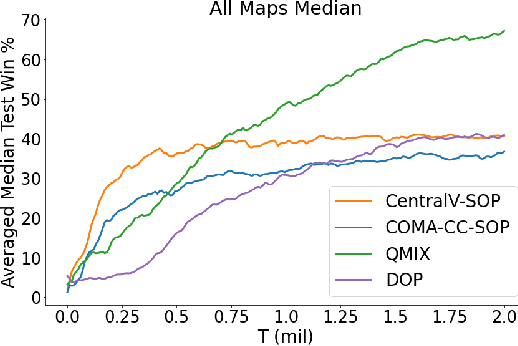
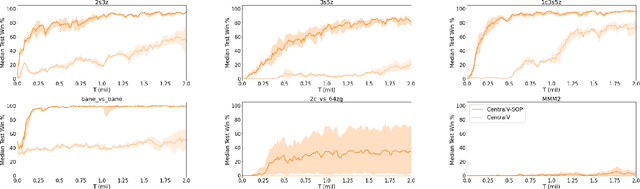
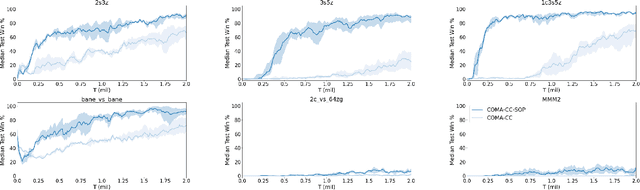
Policy gradient methods are an attractive approach to multi-agent reinforcement learning problems due to their convergence properties and robustness in partially observable scenarios. However, there is a significant performance gap between state-of-the-art policy gradient and value-based methods on the popular StarCraft Multi-Agent Challenge (SMAC) benchmark. In this paper, we introduce semi-on-policy (SOP) training as an effective and computationally efficient way to address the sample inefficiency of on-policy policy gradient methods. We enhance two state-of-the-art policy gradient algorithms with SOP training, demonstrating significant performance improvements. Furthermore, we show that our methods perform as well or better than state-of-the-art value-based methods on a variety of SMAC tasks.