 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Androids Dream of Electric Fences? Safety-Aware Reinforcement Learning with Latent Shielding
Dec 21, 2021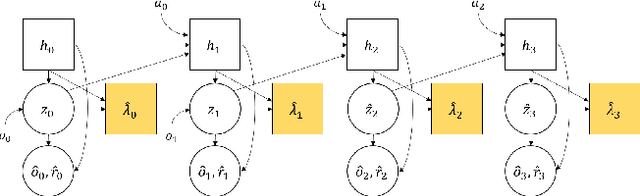


The growing trend of fledgling reinforcement learning systems making their way into real-world applications has been accompanied by growing concerns for their safety and robustness. In recent years, a variety of approaches have been put forward to address the challenges of safety-aware reinforcement learning; however, these methods often either require a handcrafted model of the environment to be provided beforehand, or that the environment is relatively simple and low-dimensional. We present a novel approach to safety-aware deep reinforcement learning in high-dimensional environments called latent shielding. Latent shielding leverages internal representations of the environment learnt by model-based agents to "imagine" future trajectories and avoid those deemed unsafe. We experimentally demonstrate that this approach leads to improved adherence to formally-defined safety specifications.
Systematic Generalisation through Task Temporal Logic and Deep Reinforcement Learning
Jun 12, 2020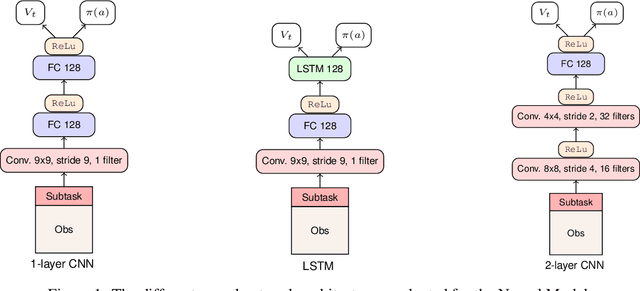


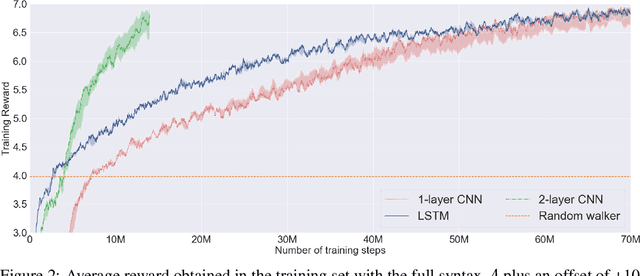
This paper presents a neuro-symbolic agent that combines deep reinforcement learning (DRL) with temporal logic (TL), and achieves systematic out-of-distribution generalisation in tasks that involve following a formally specified instruction. Specifically, the agent learns general notions of negation and disjunction, and successfully applies them to previously unseen objects without further training. To this end, we also introduce Task Temporal Logic (TTL), a learning-oriented formal language, whose atoms are designed to help the training of a DRL agent targeting systematic generalisation. To validate this combination of logic-based and neural-network techniques, we provide experimental evidence for the kind of neural-network architecture that most enhances the generalisation performance of the agent. Our findings suggest that the right architecture can significatively improve the ability of the agent to generalise in systematic ways, even with abstract operators, such as negation, which previous research have struggled with.