 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOSEIDON: Physics-Optimized Seismic Energy Inference and Detection Operating Network
Jan 05, 2026Earthquake prediction and seismic hazard assessment remain fundamental challenges in geophysics, with existing machine learning approaches often operating as black boxes that ignore established physical laws. We introduce POSEIDON (Physics-Optimized Seismic Energy Inference and Detection Operating Network), a physics-informed energy-based model for unified multi-task seismic event prediction, alongside the Poseidon dataset -- the largest open-source global earthquake catalog comprising 2.8 million events spanning 30 years. POSEIDON embeds fundamental seismological principles, including the Gutenberg-Richter magnitude-frequency relationship and Omori-Utsu aftershock decay law, as learnable constraints within an energy-based modeling framework. The architecture simultaneously addresses three interconnected prediction tasks: aftershock sequence identification, tsunami generation potential, and foreshock detection. Extensive experiments demonstrate that POSEIDON achieves state-of-the-art performance across all tasks, outperforming gradient boosting, random forest, and CNN baselines with the highest average F1 score among all compared methods. Crucially, the learned physics parameters converge to scientifically interpretable values -- Gutenberg-Richter b-value of 0.752 and Omori-Utsu parameters p=0.835, c=0.1948 days -- falling within established seismological ranges while enhancing rather than compromising predictive accuracy. The Poseidon dataset is publicly available at https://huggingface.co/datasets/BorisKriuk/Poseidon, providing pre-computed energy features, spatial grid indices, and standardized quality metrics to advance physics-informed seismic research.
MorphBoost: Self-Organizing Universal Gradient Boosting with Adaptive Tree Morphing
Nov 17, 2025Traditional gradient boosting algorithms employ static tree structures with fixed splitting criteria that remain unchanged throughout training, limiting their ability to adapt to evolving gradient distributions and problem-specific characteristics across different learning stages. This work introduces MorphBoost, a new gradient boosting framework featuring self-organizing tree structures that dynamically morph their splitting behavior during training. The algorithm implements adaptive split functions that evolve based on accumulated gradient statistics and iteration-dependent learning pressures, enabling automatic adjustment to problem complexity. Key innovations include: (1) morphing split criterion combining gradient-based scores with information-theoretic metrics weighted by training progress; (2) automatic problem fingerprinting for intelligent parameter configuration across binary/multiclass/regression tasks; (3) vectorized tree prediction achieving significant computational speedups; (4) interaction-aware feature importance detecting multiplicative relationships; and (5) fast-mode optimization balancing speed and accuracy. Comprehensive benchmarking across 10 diverse datasets against competitive models (XGBoost, LightGBM, GradientBoosting, HistGradientBoosting, ensemble methods) demonstrates that MorphBoost achieves state-of-the-art performance, outperforming XGBoost by 0.84% on average. MorphBoost secured the overall winner position with 4/10 dataset wins (40% win rate) and 6/30 top-3 finishes (20%), while maintaining the lowest variance (σ=0.0948) and highest minimum accuracy across all models, revealing superior consistency and robustness. Performance analysis across difficulty levels shows competitive results on easy datasets while achieving notable improvements on advanced problems due to higher adaptation levels.
Hybrid Physics-ML Framework for Pan-Arctic Permafrost Infrastructure Risk at Record 2.9-Million Observation Scale
Oct 02, 2025
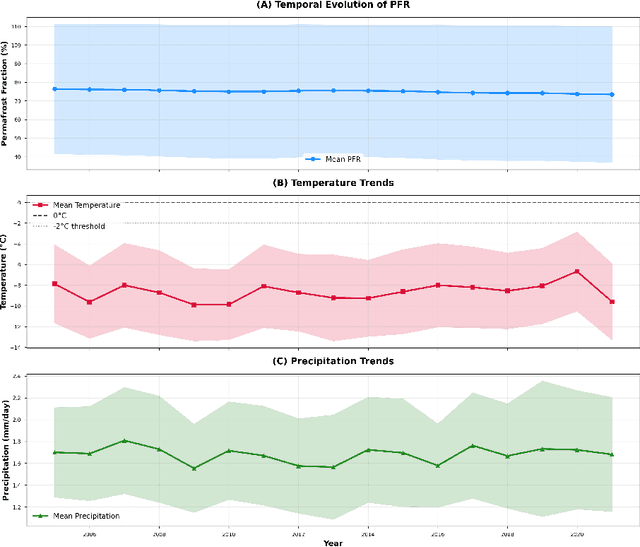


Arctic warming threatens over 100 billion in permafrost-dependent infrastructure across Northern territories, yet existing risk assessment frameworks lack spatiotemporal validation, uncertainty quantification, and operational decision-support capabilities. We present a hybrid physics-machine learning framework integrating 2.9 million observations from 171,605 locations (2005-2021) combining permafrost fraction data with climate reanalysis. Our stacked ensemble model (Random Forest + Histogram Gradient Boosting + Elastic Net) achieves R2=0.980 (RMSE=5.01 pp) with rigorous spatiotemporal cross-validation preventing data leakage. To address machine learning limitations in extrapolative climate scenarios, we develop a hybrid approach combining learned climate-permafrost relationships (60%) with physical permafrost sensitivity models (40%, -10 pp/C). Under RCP8.5 forcing (+5C over 10 years), we project mean permafrost fraction decline of -20.3 pp (median: -20.0 pp), with 51.5% of Arctic Russia experiencing over 20 percentage point loss. Infrastructure risk classification identifies 15% high-risk zones (25% medium-risk) with spatially explicit uncertainty maps. Our framework represents the largest validated permafrost ML dataset globally, provides the first operational hybrid physics-ML forecasting system for Arctic infrastructure, and delivers open-source tools enabling probabilistic permafrost projections for engineering design codes and climate adaptation planning. The methodology is generalizable to other permafrost regions and demonstrates how hybrid approaches can overcome pure data-driven limitations in climate change applications.
GeloVec: Higher Dimensional Geometric Smoothing for Coherent Visual Feature Extraction in Image Segmentation
May 02, 2025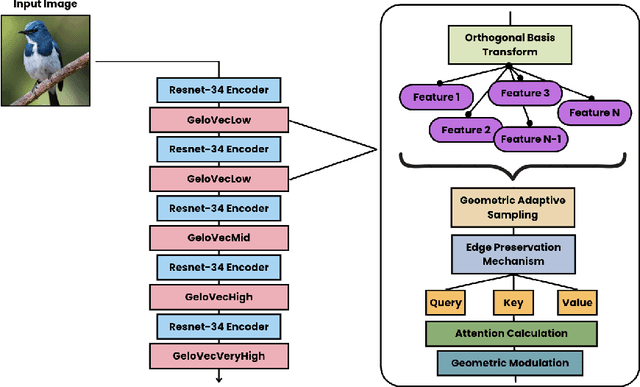
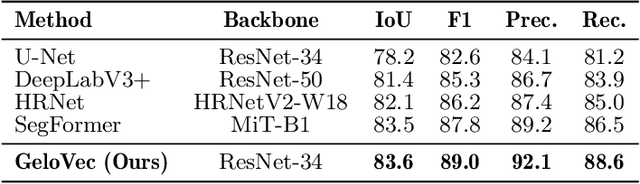


This paper introduces GeloVec, a new CNN-based attention smoothing framework for semantic segmentation that addresses critical limitations in conventional approaches. While existing attention-backed segmentation methods suffer from boundary instability and contextual discontinuities during feature mapping, our framework implements a higher-dimensional geometric smoothing method to establish a robust manifold relationships between visually coherent regions. GeloVec combines modified Chebyshev distance metrics with multispatial transformations to enhance segmentation accuracy through stabilized feature extraction. The core innovation lies in the adaptive sampling weights system that calculates geometric distances in n-dimensional feature space, achieving superior edge preservation while maintaining intra-class homogeneity. The multispatial transformation matrix incorporates tensorial projections with orthogonal basis vectors, creating more discriminative feature representations without sacrificing computational efficiency. Experimental validation across multiple benchmark datasets demonstrates significant improvements in segmentation performance, with mean Intersection over Union (mIoU) gains of 2.1%, 2.7%, and 2.4% on Caltech Birds-200, LSDSC, and FSSD datasets respectively compared to state-of-the-art methods. GeloVec's mathematical foundation in Riemannian geometry provides theoretical guarantees on segmentation stability. Importantly, our framework maintains computational efficiency through parallelized implementation of geodesic transformations and exhibits strong generalization capabilities across disciplines due to the absence of information loss during transformations.
GFT: Gradient Focal Transformer
Apr 14, 2025



Fine-Grained Image Classification (FGIC) remains a complex task in computer vision, as it requires models to distinguish between categories with subtle localized visual differences. Well-studied CNN-based models, while strong in local feature extraction, often fail to capture the global context required for fine-grained recognition, while more recent ViT-backboned models address FGIC with attention-driven mechanisms but lack the ability to adaptively focus on truly discriminative regions. TransFG and other ViT-based extensions introduced part-aware token selection to enhance attention localization, yet they still struggle with computational efficiency, attention region selection flexibility, and detail-focus narrative in complex environments. This paper introduces GFT (Gradient Focal Transformer), a new ViT-derived framework created for FGIC tasks. GFT integrates the Gradient Attention Learning Alignment (GALA) mechanism to dynamically prioritize class-discriminative features by analyzing attention gradient flow. Coupled with a Progressive Patch Selection (PPS) strategy, the model progressively filters out less informative regions, reducing computational overhead while enhancing sensitivity to fine details. GFT achieves SOTA accuracy on FGVC Aircraft, Food-101, and COCO datasets with 93M parameters, outperforming ViT-based advanced FGIC models in efficiency. By bridging global context and localized detail extraction, GFT sets a new benchmark in fine-grained recognition, offering interpretable solutions for real-world deployment scenarios.
Advancing Eurasia Fire Understanding Through Machine Learning Techniques
Feb 24, 2025Modern fire management systems increasingly rely on satellite data and weather forecasting; however, access to comprehensive datasets remains limited due to proprietary restrictions. Despite the ecological significance of wildfires, large-scale, multi-regional research is constrained by data scarcity. Russian diverse ecosystems play a crucial role in shaping Eurasian fire dynamics, yet they remain underexplored. This study addresses existing gaps by introducing an open-access dataset that captures detailed fire incidents alongside corresponding meteorological conditions. We present one of the most extensive datasets available for wildfire analysis in Russia, covering 13 consecutive months of observations. Leveraging machine learning techniques, we conduct exploratory data analysis and develop predictive models to identify key fire behavior patterns across different fire categories and ecosystems. Our results highlight the critical influence of environmental factor patterns on fire occurrence and spread behavior. By improving the understanding of wildfire dynamics in Eurasia, this work contributes to more effective, data-driven approaches for proactive fire management in the face of evolving environmental conditions.
ELENA: Epigenetic Learning through Evolved Neural Adaptation
Jan 10, 2025



Despite the success of metaheuristic algorithms in solving complex network optimization problems, they often struggle with adaptation, especially in dynamic or high-dimensional search spaces. Traditional approaches can become stuck in local optima, leading to inefficient exploration and suboptimal solutions. Most of the widely accepted advanced algorithms do well either on highly complex or smaller search spaces due to the lack of adaptation. To address these limitations, we present ELENA (Epigenetic Learning through Evolved Neural Adaptation), a new evolutionary framework that incorporates epigenetic mechanisms to enhance the adaptability of the core evolutionary approach. ELENA leverages compressed representation of learning parameters improved dynamically through epigenetic tags that serve as adaptive memory. Three epigenetic tags (mutation resistance, crossover affinity, and stability score) assist with guiding solution space search, facilitating a more intelligent hypothesis landscape exploration. To assess the framework performance, we conduct experiments on three critical network optimization problems: the Traveling Salesman Problem (TSP), the Vehicle Routing Problem (VRP), and the Maximum Clique Problem (MCP). Experiments indicate that ELENA achieves competitive results, often surpassing state-of-the-art methods on network optimization tasks.
CharNet: Generalized Approach for High-Complexity Character Classification
Jan 30, 2024Handwritten character recognition (HCR) is a challenging problem for machine learning researchers. Unlike printed text data, handwritten character datasets have more variation due to human-introduced bias. With numerous unique character classes present, some data, such as Logographic Scripts or Sino-Korean character sequences, bring new complications to the HCR problem. The classification task on such datasets requires the model to learn high-complexity details of the images that share similar features. With recent advances in computational resource availability and further computer vision theory development, some research teams have effectively addressed the arising challenges. Although known for achieving high efficiency, many common approaches are still not generalizable and use dataset-specific solutions to achieve better results. Due to complex structure and high computing demands, existing methods frequently prevent the solutions from gaining popularity. This paper proposes a straightforward, generalizable, and highly effective approach (CharNet) for detailed character image classification and compares its performance to that of existing approaches.