 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Preference Learning: a Decision Tree-based Surrogate Model for Preferential Bayesian Optimization
Dec 16, 2025Current Preferential Bayesian Optimization methods rely on Gaussian Processes (GPs) as surrogate models. These models are hard to interpret, struggle with handling categorical data, and are computationally complex, limiting their real-world usability. In this paper, we introduce an inherently interpretable decision tree-based surrogate model capable of handling both categorical and continuous data, and scalable to large datasets. Extensive numerical experiments on eight increasingly spiky optimization functions show that our model outperforms GP-based alternatives on spiky functions and has only marginally lower performance for non-spiky functions. Moreover, we apply our model to the real-world Sushi dataset and show its ability to learn an individual's sushi preferences. Finally, we show some initial work on using historical preference data to speed up the optimization process for new unseen users.
Efficient pattern-based anomaly detection in a network of multivariate devices
May 07, 2023



Many organisations manage service quality and monitor a large set devices and servers where each entity is associated with telemetry or physical sensor data series. Recently, various methods have been proposed to detect behavioural anomalies, however existing approaches focus on multivariate time series and ignore communication between entities. Moreover, we aim to support end-users in not only in locating entities and sensors causing an anomaly at a certain period, but also explain this decision. We propose a scalable approach to detect anomalies using a two-step approach. First, we recover relations between entities in the network, since relations are often dynamic in nature and caused by an unknown underlying process. Next, we report anomalies based on an embedding of sequential patterns. Pattern mining is efficient and supports interpretation, i.e. patterns represent frequent occurring behaviour in time series. We extend pattern mining to filter sequential patterns based on frequency, temporal constraints and minimum description length. We collect and release two public datasets for international broadcasting and X from an Internet company. \textit{BAD} achieves an overall F1-Score of 0.78 on 9 benchmark datasets, significantly outperforming the best baseline by 3\%. Additionally, \textit{BAD} is also an order-of-magnitude faster than state-of-the-art anomaly detection methods.
Mining Closed Strict Episodes
Apr 24, 2019

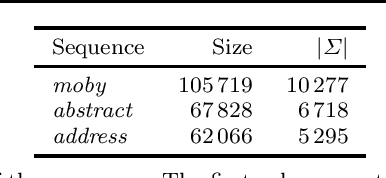
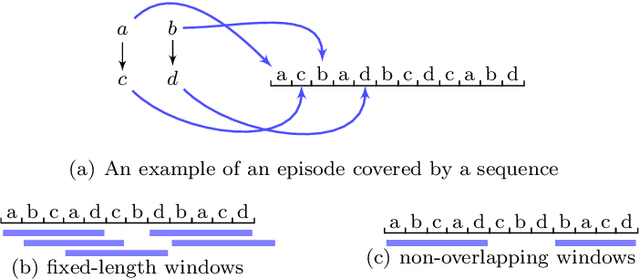
Discovering patterns in a sequence is an important aspect of data mining. One popular choice of such patterns are episodes, patterns in sequential data describing events that often occur in the vicinity of each other. Episodes also enforce in which order the events are allowed to occur. In this work we introduce a technique for discovering closed episodes. Adopting existing approaches for discovering traditional patterns, such as closed itemsets, to episodes is not straightforward. First of all, we cannot define a unique closure based on frequency because an episode may have several closed superepisodes. Moreover, to define a closedness concept for episodes we need a subset relationship between episodes, which is not trivial to define. We approach these problems by introducing strict episodes. We argue that this class is general enough, and at the same time we are able to define a natural subset relationship within it and use it efficiently. In order to mine closed episodes we define an auxiliary closure operator. We show that this closure satisfies the needed properties so that we can use the existing framework for mining closed patterns. Discovering the true closed episodes can be done as a post-processing step. We combine these observations into an efficient mining algorithm and demonstrate empirically its performance in practice.
Mining Closed Episodes with Simultaneous Events
Apr 16, 2019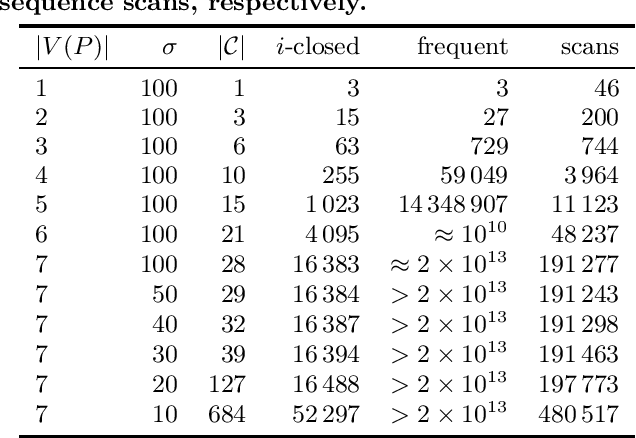
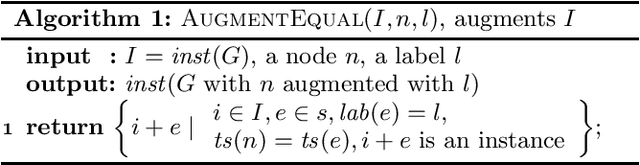
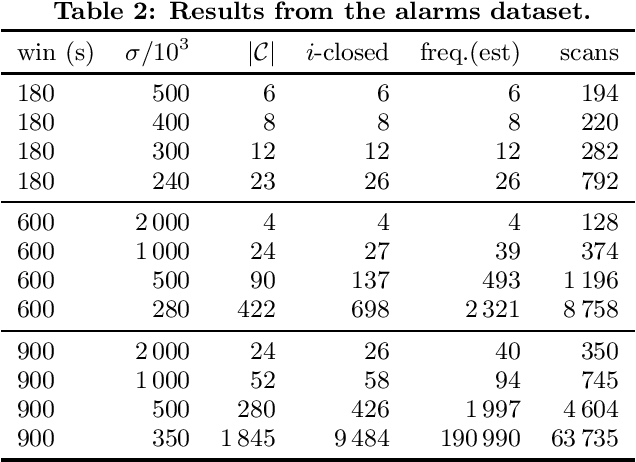

Sequential pattern discovery is a well-studied field in data mining. Episodes are sequential patterns describing events that often occur in the vicinity of each other. Episodes can impose restrictions to the order of the events, which makes them a versatile technique for describing complex patterns in the sequence. Most of the research on episodes deals with special cases such as serial, parallel, and injective episodes, while discovering general episodes is understudied. In this paper we extend the definition of an episode in order to be able to represent cases where events often occur simultaneously. We present an efficient and novel miner for discovering frequent and closed general episodes. Such a task presents unique challenges. Firstly, we cannot define closure based on frequency. We solve this by computing a more conservative closure that we use to reduce the search space and discover the closed episodes as a postprocessing step. Secondly, episodes are traditionally presented as directed acyclic graphs. We argue that this representation has drawbacks leading to redundancy in the output. We solve these drawbacks by defining a subset relationship in such a way that allows us to remove the redundant episodes. We demonstrate the efficiency of our algorithm and the need for using closed episodes empirically on synthetic and real-world datasets.