 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilter Pruning For CNN With Enhanced Linear Representation Redundancy
Oct 10, 2023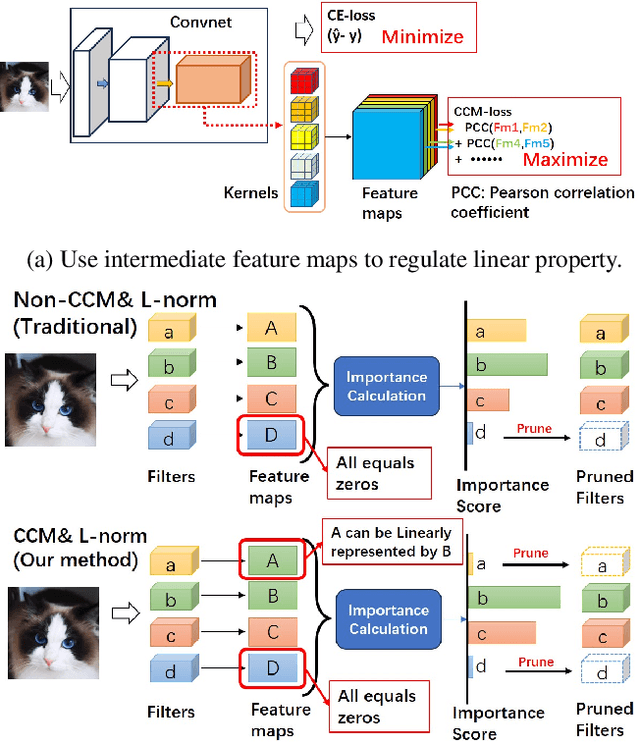
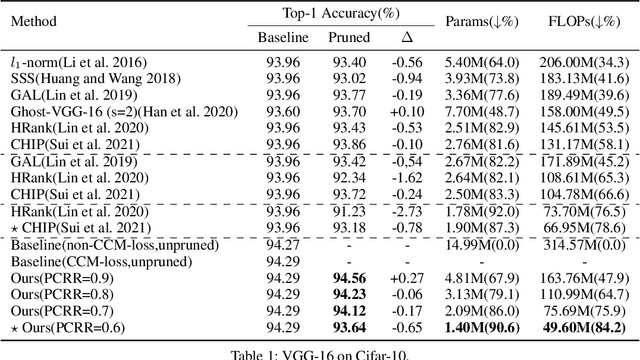
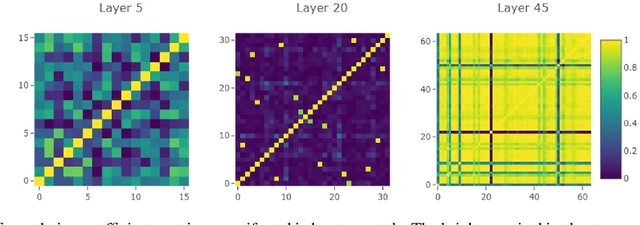
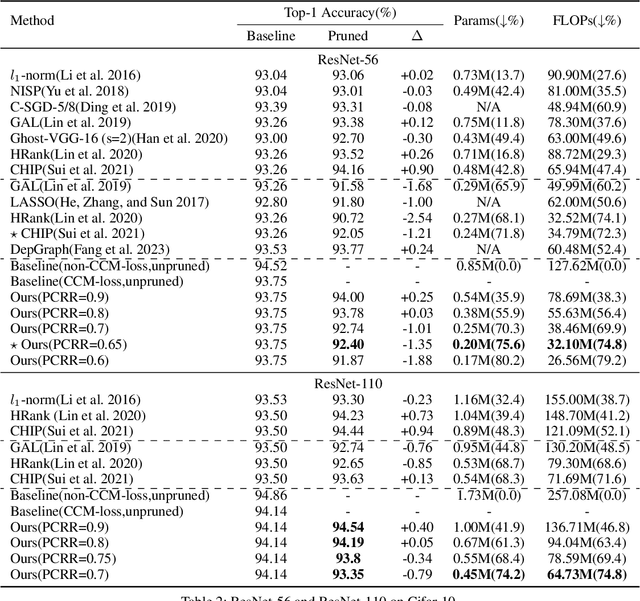
Structured network pruning excels non-structured methods because they can take advantage of the thriving developed parallel computing techniques. In this paper, we propose a new structured pruning method. Firstly, to create more structured redundancy, we present a data-driven loss function term calculated from the correlation coefficient matrix of different feature maps in the same layer, named CCM-loss. This loss term can encourage the neural network to learn stronger linear representation relations between feature maps during the training from the scratch so that more homogenous parts can be removed later in pruning. CCM-loss provides us with another universal transcendental mathematical tool besides L*-norm regularization, which concentrates on generating zeros, to generate more redundancy but for the different genres. Furthermore, we design a matching channel selection strategy based on principal components analysis to exploit the maximum potential ability of CCM-loss. In our new strategy, we mainly focus on the consistency and integrality of the information flow in the network. Instead of empirically hard-code the retain ratio for each layer, our channel selection strategy can dynamically adjust each layer's retain ratio according to the specific circumstance of a per-trained model to push the prune ratio to the limit. Notably, on the Cifar-10 dataset, our method brings 93.64% accuracy for pruned VGG-16 with only 1.40M parameters and 49.60M FLOPs, the pruned ratios for parameters and FLOPs are 90.6% and 84.2%, respectively. For ResNet-50 trained on the ImageNet dataset, our approach achieves 42.8% and 47.3% storage and computation reductions, respectively, with an accuracy of 76.23%. Our code is available at https://github.com/Bojue-Wang/CCM-LRR.