 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly-Optimal Hierarchical Clustering for Well-Clustered Graphs
Jun 16, 2023



This paper presents two efficient hierarchical clustering (HC) algorithms with respect to Dasgupta's cost function. For any input graph $G$ with a clear cluster-structure, our designed algorithms run in nearly-linear time in the input size of $G$, and return an $O(1)$-approximate HC tree with respect to Dasgupta's cost function. We compare the performance of our algorithm against the previous state-of-the-art on synthetic and real-world datasets and show that our designed algorithm produces comparable or better HC trees with much lower running time.
Hierarchical Clustering: $O(1)$-Approximation for Well-Clustered Graphs
Dec 16, 2021

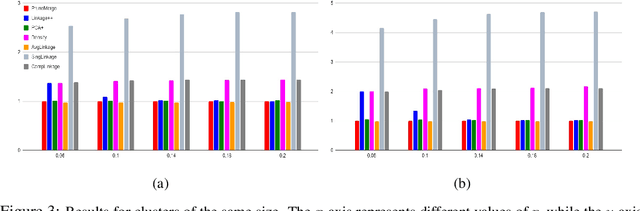

Hierarchical clustering studies a recursive partition of a data set into clusters of successively smaller size, and is a fundamental problem in data analysis. In this work we study the cost function for hierarchical clustering introduced by Dasgupta, and present two polynomial-time approximation algorithms: Our first result is an $O(1)$-approximation algorithm for graphs of high conductance. Our simple construction bypasses complicated recursive routines of finding sparse cuts known in the literature. Our second and main result is an $O(1)$-approximation algorithm for a wide family of graphs that exhibit a well-defined structure of clusters. This result generalises the previous state-of-the-art, which holds only for graphs generated from stochastic models. The significance of our work is demonstrated by the empirical analysis on both synthetic and real-world data sets, on which our presented algorithm outperforms the previously proposed algorithm for graphs with a well-defined cluster structure.