 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Copeland Winners in Dueling Bandits with Indifferences
Oct 01, 2023We consider the task of identifying the Copeland winner(s) in a dueling bandits problem with ternary feedback. This is an underexplored but practically relevant variant of the conventional dueling bandits problem, in which, in addition to strict preference between two arms, one may observe feedback in the form of an indifference. We provide a lower bound on the sample complexity for any learning algorithm finding the Copeland winner(s) with a fixed error probability. Moreover, we propose POCOWISTA, an algorithm with a sample complexity that almost matches this lower bound, and which shows excellent empirical performance, even for the conventional dueling bandits problem. For the case where the preference probabilities satisfy a specific type of stochastic transitivity, we provide a refined version with an improved worst case sample complexity.
AC-Band: A Combinatorial Bandit-Based Approach to Algorithm Configuration
Dec 01, 2022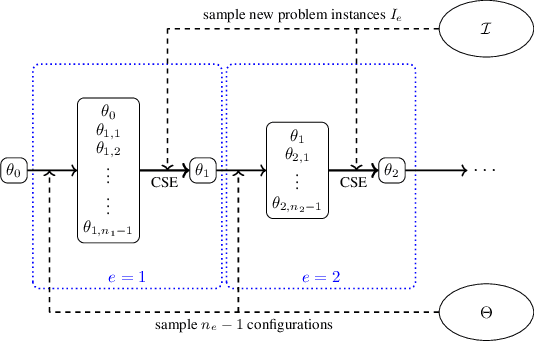

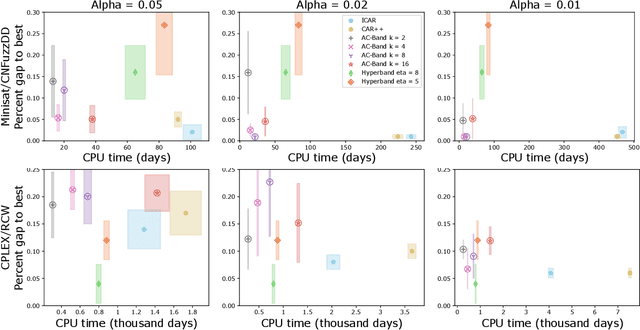

We study the algorithm configuration (AC) problem, in which one seeks to find an optimal parameter configuration of a given target algorithm in an automated way. Recently, there has been significant progress in designing AC approaches that satisfy strong theoretical guarantees. However, a significant gap still remains between the practical performance of these approaches and state-of-the-art heuristic methods. To this end, we introduce AC-Band, a general approach for the AC problem based on multi-armed bandits that provides theoretical guarantees while exhibiting strong practical performance. We show that AC-Band requires significantly less computation time than other AC approaches providing theoretical guarantees while still yielding high-quality configurations.
Finding Optimal Arms in Non-stochastic Combinatorial Bandits with Semi-bandit Feedback and Finite Budget
Feb 09, 2022



We consider the combinatorial bandits problem with semi-bandit feedback under finite sampling budget constraints, in which the learner can carry out its action only for a limited number of times specified by an overall budget. The action is to choose a set of arms, whereupon feedback for each arm in the chosen set is received. Unlike existing works, we study this problem in a non-stochastic setting with subset-dependent feedback, i.e., the semi-bandit feedback received could be generated by an oblivious adversary and also might depend on the chosen set of arms. In addition, we consider a general feedback scenario covering both the numerical-based as well as preference-based case and introduce a sound theoretical framework for this setting guaranteeing sensible notions of optimal arms, which a learner seeks to find. We suggest a generic algorithm suitable to cover the full spectrum of conceivable arm elimination strategies from aggressive to conservative. Theoretical questions about the sufficient and necessary budget of the algorithm to find the best arm are answered and complemented by deriving lower bounds for any learning algorithm for this problem scenario.