 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Principal Subspace Analysis for Partitioned Big Data: Algorithms, Analysis, and Implementation
Mar 11, 2021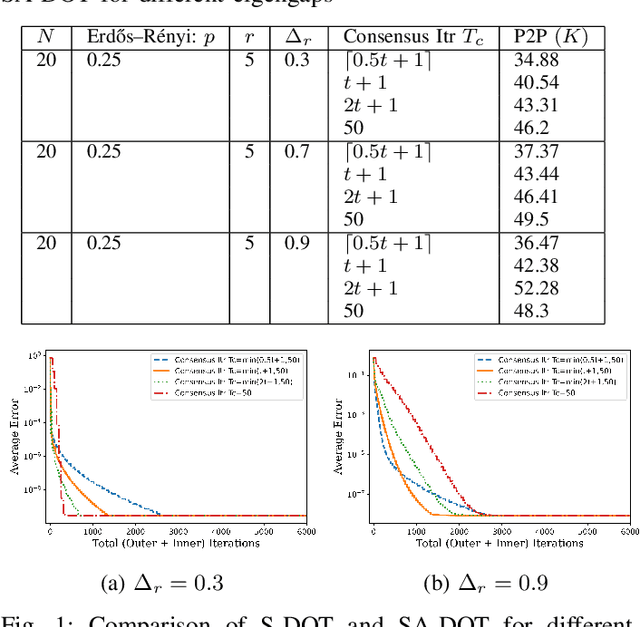
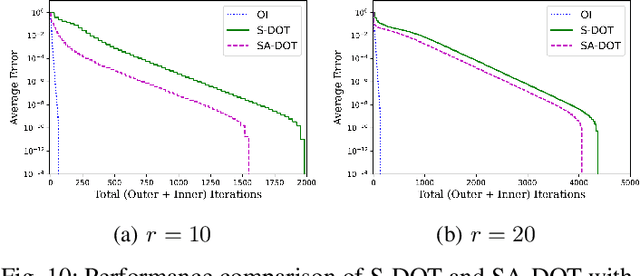
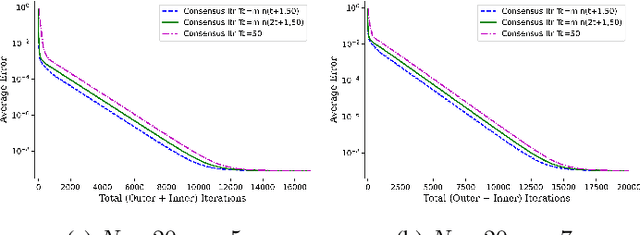
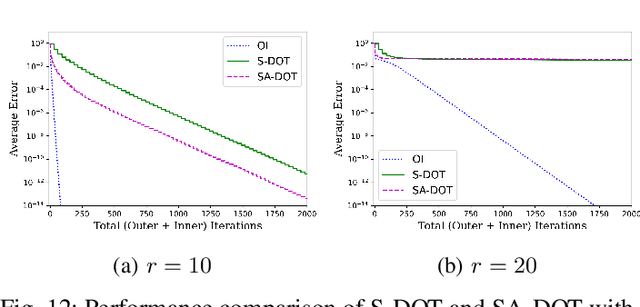
Principal Subspace Analysis (PSA) is one of the most popular approaches for dimensionality reduction in signal processing and machine learning. But centralized PSA solutions are fast becoming irrelevant in the modern era of big data, in which the number of samples and/or the dimensionality of samples often exceed the storage and/or computational capabilities of individual machines. This has led to study of distributed PSA solutions, in which the data are partitioned across multiple machines and an estimate of the principal subspace is obtained through collaboration among the machines. It is in this vein that this paper revisits the problem of distributed PSA under the general framework of an arbitrarily connected network of machines that lacks a central server. The main contributions of the paper in this regard are threefold. First, two algorithms are proposed in the paper that can be used for distributed PSA in the case of data that are partitioned across either samples or (raw) features. Second, in the case of sample-wise partitioned data, the proposed algorithm and a variant of it are analyzed, and their convergence to the true subspace at linear rates is established. Third, extensive experiments on both synthetic and real-world data are carried out to validate the usefulness of the proposed algorithms. In particular, in the case of sample-wise partitioned data, an MPI-based distributed implementation is carried out to study the interplay between network topology and communications cost as well as to study of effect of straggler machines on the proposed algorithms.