 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP-based Regulatory Compliance -- Using GPT 4.0 to Decode Regulatory Documents
Dec 29, 2024Large Language Models (LLMs) such as GPT-4.0 have shown significant promise in addressing the semantic complexities of regulatory documents, particularly in detecting inconsistencies and contradictions. This study evaluates GPT-4.0's ability to identify conflicts within regulatory requirements by analyzing a curated corpus with artificially injected ambiguities and contradictions, designed in collaboration with architects and compliance engineers. Using metrics such as precision, recall, and F1 score, the experiment demonstrates GPT-4.0's effectiveness in detecting inconsistencies, with findings validated by human experts. The results highlight the potential of LLMs to enhance regulatory compliance processes, though further testing with larger datasets and domain-specific fine-tuning is needed to maximize accuracy and practical applicability. Future work will explore automated conflict resolution and real-world implementation through pilot projects with industry partners.
SPaR.txt, a cheap Shallow Parsing approach for Regulatory texts
Oct 04, 2021
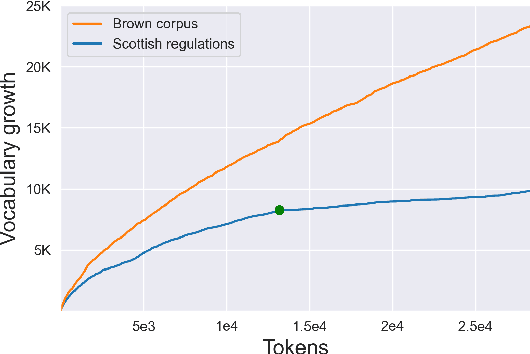
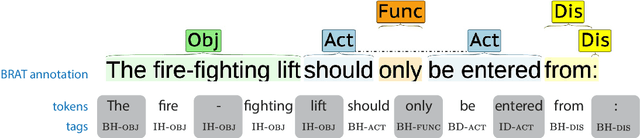
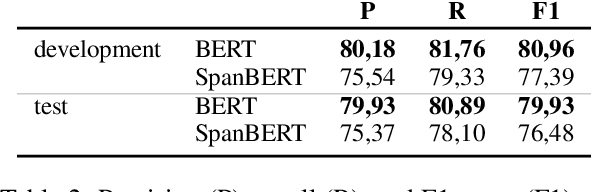
Automated Compliance Checking (ACC) systems aim to semantically parse building regulations to a set of rules. However, semantic parsing is known to be hard and requires large amounts of training data. The complexity of creating such training data has led to research that focuses on small sub-tasks, such as shallow parsing or the extraction of a limited subset of rules. This study introduces a shallow parsing task for which training data is relatively cheap to create, with the aim of learning a lexicon for ACC. We annotate a small domain-specific dataset of 200 sentences, SPaR.txt, and train a sequence tagger that achieves 79,93 F1-score on the test set. We then show through manual evaluation that the model identifies most (89,84%) defined terms in a set of building regulation documents, and that both contiguous and discontiguous Multi-Word Expressions (MWE) are discovered with reasonable accuracy (70,3%).