 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQARIMA: A Quantum Approach To Classical Time Series Analysis
Apr 09, 2026We present a quantum-inspired ARIMA methodology that integrates quantum-assisted lag discovery with \emph{fixed-configuration} variational quantum circuits (VQCs) for parameter estimation and weak-lag refinement. Differencing and candidate lags are identified via swap-test-driven quantum autocorrelation (QACF) and quantum partial autocorrelation (QPACF), with a delayed-matrix construction that aligns quantum projections to time-domain regressors, followed by standard information-criterion parsimony. Given the screened orders $(p,d,q)$, we retain a fixed VQC ansatz, optimizer, and training budget, preventing hyperparameter leakage, and deploy the circuit in two estimation roles: VQC-AR for autoregressive coefficients and VQC-MA for moving-average coefficients. Between screening and estimation, a lightweight VQC weak-lag refinement re-weights or prunes screened AR lags without altering $(p,d,q)$. Across environmental and industrial datasets, we perform rolling-origin evaluations against automated classical ARIMA, reporting out-of-sample mean squared error (MSE), mean absolute percentage error (MAPE), and Diebold--Mariano tests on MSE and MAE. Empirically, the seven quantum contributions -- (1) differencing selection, (2) QACF, (3) QPACF, (4) swap-test primitives with delayed-matrix construction, (5) VQC-AR, (6) VQC weak-lag refinement, and (7) VQC-MA -- collectively reduce meta-optimization overhead and make explicit where quantum effects enter order discovery, lag refinement, and AR/MA parameter estimation.
Unsharp Measurement with Adaptive Gaussian POVMs for Quantum-Inspired Image Processing
Apr 06, 2026We propose a quantum measurement-based framework for probabilistic transformation of grayscale images using adaptive positive operator-valued measures (POVMs). In contrast, to existing approaches that are largely centered around segmentation or thresholding, the transformation is formulated here as a measurement-induced process acting directly on pixel intensities. The intensity values are embedded in a finite-dimensional Hilbert space, which allows the construction of data-adaptive measurement operators derived from Gaussian models of the image histogram. These operators naturally define an unsharp measurement of the intensity observable, with the reconstructed image obtained through expectation values of the measurement outcomes. To control the degree of measurement localization, we introduce a nonlinear sharpening transformation with a sharpening parameter, $γ$, that induces a continuous transition from unsharp measurements to projective measurements. This transition reflects an inherent trade-off between probabilistic smoothing and localization of intensity structures. In addition to the nonlinear sharpening parameter, we introduce another parameter $k$ (number of gaussian centers) which controls the resolution of the image during the transformation. Experimental results on standard benchmark images show that the proposed method gives effective data-adaptive transformations while preserving structural information.
Quantum-Inspired Geometric Classification with Correlation Group Structures and VQC Decision Modeling
Apr 02, 2026We propose a geometry-driven quantum-inspired classification framework that integrates Correlation Group Structures (CGR), compact SWAP-test-based overlap estimation, and selective variational quantum decision modelling. Rather than directly approximating class posteriors, the method adopts a geometry-first paradigm in which samples are evaluated relative to class medoids using overlap-derived Euclidean-like and angular similarity channels. CGR organizes features into anchor-centered correlation neighbourhoods, generating nonlinear, correlation-weighted representations that enhance robustness in heterogeneous tabular spaces. These geometric signals are fused through a non-probabilistic margin-based fusion score, serving as a lightweight and data-efficient primary classifier for small-to-moderate datasets. On Heart Disease, Breast Cancer, and Wine Quality datasets, the fusion-score classifier achieves 0.8478, 0.8881, and 0.9556 test accuracy respectively, with macro-F1 scores of 0.8463, 0.8703, and 0.9522, demonstrating competitive and stable performance relative to classical baselines. For large-scale and highly imbalanced regimes, we construct compact Delta-distance contrastive features and train a variational quantum classifier (VQC) as a nonlinear refinement layer. On the Credit Card Fraud dataset (0.17% prevalence), the Delta + VQC pipeline achieves approximately 0.85 minority recall at an alert rate of approximately 1.31%, with ROC-AUC 0.9249 and PR-AUC 0.3251 under full-dataset evaluation. These results highlight the importance of operating-point-aware assessment in rare-event detection and demonstrate that the proposed hybrid geometric-variational framework provides interpretable, scalable, and regime-adaptive classification across heterogeneous data settings.
QSMOTE-PGM/kPGM: QSMOTE Based PGM and kPGM for Imbalanced Dataset Classification
Dec 18, 2025Quantum-inspired machine learning (QiML) leverages mathematical frameworks from quantum theory to enhance classical algorithms, with particular emphasis on inner product structures in high-dimensional feature spaces. Among the prominent approaches, the Kernel Trick, widely used in support vector machines, provides efficient similarity computation, while the Pretty Good Measurement (PGM), originating from quantum state discrimination, enables classification grounded in Hilbert space geometry. Building on recent developments in kernelized PGM (KPGM) and direct PGM-based classifiers, this work presents a unified theoretical and empirical comparison of these paradigms. We analyze their performance across synthetic oversampling scenarios using Quantum SMOTE (QSMOTE) variants. Experimental results show that both PGM and KPGM classifiers consistently outperform a classical random forest baseline, particularly when multiple quantum copies are employed. Notably, PGM with stereo encoding and n_copies=2 achieves the highest overall accuracy (0.8512) and F1-score (0.8234), while KPGM demonstrates competitive and more stable behavior across QSMOTE variants, with top scores of 0.8511 (stereo) and 0.8483 (amplitude). These findings highlight that quantum-inspired classifiers not only provide tangible gains in recall and balanced performance but also offer complementary strengths: PGM benefits from encoding-specific enhancements, whereas KPGM ensures robustness across sampling strategies. Our results advance the understanding of kernel-based and measurement-based QiML methods, offering practical guidance on their applicability under varying data characteristics and computational constraints.
QSVM-QNN: Quantum Support Vector Machine Based Quantum Neural Network Learning Algorithm for Brain-Computer Interfacing Systems
May 20, 2025A brain-computer interface (BCI) system enables direct communication between the brain and external devices, offering significant potential for assistive technologies and advanced human-computer interaction. Despite progress, BCI systems face persistent challenges, including signal variability, classification inefficiency, and difficulty adapting to individual users in real time. In this study, we propose a novel hybrid quantum learning model, termed QSVM-QNN, which integrates a Quantum Support Vector Machine (QSVM) with a Quantum Neural Network (QNN), to improve classification accuracy and robustness in EEG-based BCI tasks. Unlike existing models, QSVM-QNN combines the decision boundary capabilities of QSVM with the expressive learning power of QNN, leading to superior generalization performance. The proposed model is evaluated on two benchmark EEG datasets, achieving high accuracies of 0.990 and 0.950, outperforming both classical and standalone quantum models. To demonstrate real-world viability, we further validated the robustness of QNN, QSVM, and QSVM-QNN against six realistic quantum noise models, including bit flip and phase damping. These experiments reveal that QSVM-QNN maintains stable performance under noisy conditions, establishing its applicability for deployment in practical, noisy quantum environments. Beyond BCI, the proposed hybrid quantum architecture is generalizable to other biomedical and time-series classification tasks, offering a scalable and noise-resilient solution for next-generation neurotechnological systems.
Quantum-Inspired Optimization Process for Data Imputation
May 07, 2025Data imputation is a critical step in data pre-processing, particularly for datasets with missing or unreliable values. This study introduces a novel quantum-inspired imputation framework evaluated on the UCI Diabetes dataset, which contains biologically implausible missing values across several clinical features. The method integrates Principal Component Analysis (PCA) with quantum-assisted rotations, optimized through gradient-free classical optimizers -COBYLA, Simulated Annealing, and Differential Evolution to reconstruct missing values while preserving statistical fidelity. Reconstructed values are constrained within +/-2 standard deviations of original feature distributions, avoiding unrealistic clustering around central tendencies. This approach achieves a substantial and statistically significant improvement, including an average reduction of over 85% in Wasserstein distance and Kolmogorov-Smirnov test p-values between 0.18 and 0.22, compared to p-values > 0.99 in classical methods such as Mean, KNN, and MICE. The method also eliminates zero-value artifacts and enhances the realism and variability of imputed data. By combining quantum-inspired transformations with a scalable classical framework, this methodology provides a robust solution for imputation tasks in domains such as healthcare and AI pipelines, where data quality and integrity are crucial.
QFDNN: A Resource-Efficient Variational Quantum Feature Deep Neural Networks for Fraud Detection and Loan Prediction
Apr 28, 2025
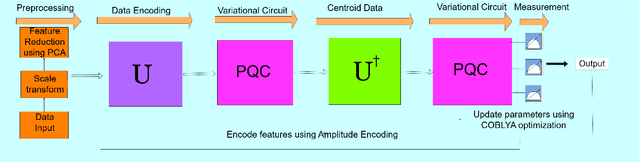
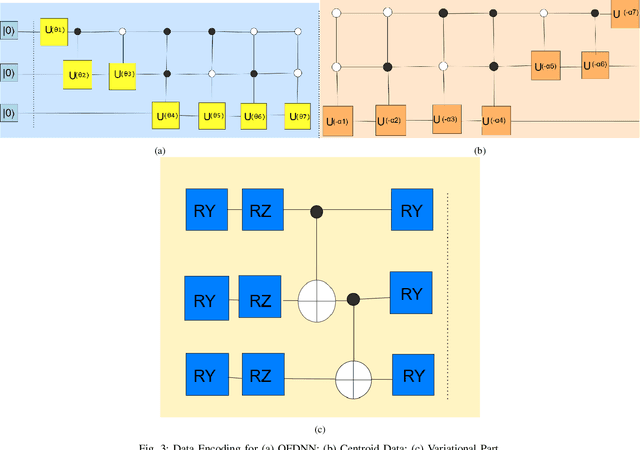

Social financial technology focuses on trust, sustainability, and social responsibility, which require advanced technologies to address complex financial tasks in the digital era. With the rapid growth in online transactions, automating credit card fraud detection and loan eligibility prediction has become increasingly challenging. Classical machine learning (ML) models have been used to solve these challenges; however, these approaches often encounter scalability, overfitting, and high computational costs due to complexity and high-dimensional financial data. Quantum computing (QC) and quantum machine learning (QML) provide a promising solution to efficiently processing high-dimensional datasets and enabling real-time identification of subtle fraud patterns. However, existing quantum algorithms lack robustness in noisy environments and fail to optimize performance with reduced feature sets. To address these limitations, we propose a quantum feature deep neural network (QFDNN), a novel, resource efficient, and noise-resilient quantum model that optimizes feature representation while requiring fewer qubits and simpler variational circuits. The model is evaluated using credit card fraud detection and loan eligibility prediction datasets, achieving competitive accuracies of 82.2% and 74.4%, respectively, with reduced computational overhead. Furthermore, we test QFDNN against six noise models, demonstrating its robustness across various error conditions. Our findings highlight QFDNN potential to enhance trust and security in social financial technology by accurately detecting fraudulent transactions while supporting sustainability through its resource-efficient design and minimal computational overhead.
Quantum SMOTE with Angular Outliers: Redefining Minority Class Handling
Jan 31, 2025This paper introduces Quantum-SMOTEV2, an advanced variant of the Quantum-SMOTE method, leveraging quantum computing to address class imbalance in machine learning datasets without K-Means clustering. Quantum-SMOTEV2 synthesizes data samples using swap tests and quantum rotation centered around a single data centroid, concentrating on the angular distribution of minority data points and the concept of angular outliers (AOL). Experimental results show significant enhancements in model performance metrics at moderate SMOTE levels (30-36%), which previously required up to 50% with the original method. Quantum-SMOTEV2 maintains essential features of its predecessor (arXiv:2402.17398), such as rotation angle, minority percentage, and splitting factor, allowing for tailored adaptation to specific dataset needs. The method is scalable, utilizing compact swap tests and low depth quantum circuits to accommodate a large number of features. Evaluation on the public Cell-to-Cell Telecom dataset with Random Forest (RF), K-Nearest Neighbours (KNN) Classifier, and Neural Network (NN) illustrates that integrating Angular Outliers modestly boosts classification metrics like accuracy, F1 Score, AUC-ROC, and AUC-PR across different proportions of synthetic data, highlighting the effectiveness of Quantum-SMOTEV2 in enhancing model performance for edge cases.
SentiQNF: A Novel Approach to Sentiment Analysis Using Quantum Algorithms and Neuro-Fuzzy Systems
Dec 17, 2024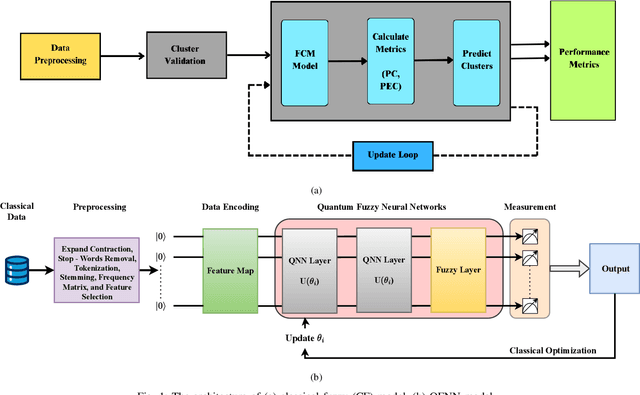

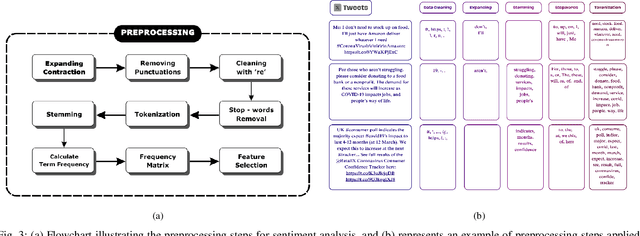
Sentiment analysis is an essential component of natural language processing, used to analyze sentiments, attitudes, and emotional tones in various contexts. It provides valuable insights into public opinion, customer feedback, and user experiences. Researchers have developed various classical machine learning and neuro-fuzzy approaches to address the exponential growth of data and the complexity of language structures in sentiment analysis. However, these approaches often fail to determine the optimal number of clusters, interpret results accurately, handle noise or outliers efficiently, and scale effectively to high-dimensional data. Additionally, they are frequently insensitive to input variations. In this paper, we propose a novel hybrid approach for sentiment analysis called the Quantum Fuzzy Neural Network (QFNN), which leverages quantum properties and incorporates a fuzzy layer to overcome the limitations of classical sentiment analysis algorithms. In this study, we test the proposed approach on two Twitter datasets: the Coronavirus Tweets Dataset (CVTD) and the General Sentimental Tweets Dataset (GSTD), and compare it with classical and hybrid algorithms. The results demonstrate that QFNN outperforms all classical, quantum, and hybrid algorithms, achieving 100% and 90% accuracy in the case of CVTD and GSTD, respectively. Furthermore, QFNN demonstrates its robustness against six different noise models, providing the potential to tackle the computational complexity associated with sentiment analysis on a large scale in a noisy environment. The proposed approach expedites sentiment data processing and precisely analyses different forms of textual data, thereby enhancing sentiment classification and insights associated with sentiment analysis.
A Quantum Approach to Synthetic Minority Oversampling Technique (SMOTE)
Feb 28, 2024The paper proposes the Quantum-SMOTE method, a novel solution that uses quantum computing techniques to solve the prevalent problem of class imbalance in machine learning datasets. Quantum-SMOTE, inspired by the Synthetic Minority Oversampling Technique (SMOTE), generates synthetic data points using quantum processes such as swap tests and quantum rotation. The process varies from the conventional SMOTE algorithm's usage of K-Nearest Neighbors (KNN) and Euclidean distances, enabling synthetic instances to be generated from minority class data points without relying on neighbor proximity. The algorithm asserts greater control over the synthetic data generation process by introducing hyperparameters such as rotation angle, minority percentage, and splitting factor, which allow for customization to specific dataset requirements. The approach is tested on a public dataset of TelecomChurn and evaluated alongside two prominent classification algorithms, Random Forest and Logistic Regression, to determine its impact along with varying proportions of synthetic data.