 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-JEPA: Augmentation-Free Self-Supervised Learning for Tabular Data
Oct 07, 2024



Self-supervision is often used for pre-training to foster performance on a downstream task by constructing meaningful representations of samples. Self-supervised learning (SSL) generally involves generating different views of the same sample and thus requires data augmentations that are challenging to construct for tabular data. This constitutes one of the main challenges of self-supervision for structured data. In the present work, we propose a novel augmentation-free SSL method for tabular data. Our approach, T-JEPA, relies on a Joint Embedding Predictive Architecture (JEPA) and is akin to mask reconstruction in the latent space. It involves predicting the latent representation of one subset of features from the latent representation of a different subset within the same sample, thereby learning rich representations without augmentations. We use our method as a pre-training technique and train several deep classifiers on the obtained representation. Our experimental results demonstrate a substantial improvement in both classification and regression tasks, outperforming models trained directly on samples in their original data space. Moreover, T-JEPA enables some methods to consistently outperform or match the performance of traditional methods likes Gradient Boosted Decision Trees. To understand why, we extensively characterize the obtained representations and show that T-JEPA effectively identifies relevant features for downstream tasks without access to the labels. Additionally, we introduce regularization tokens, a novel regularization method critical for training of JEPA-based models on structured data.
Making Parametric Anomaly Detection on Tabular Data Non-Parametric Again
Jan 30, 2024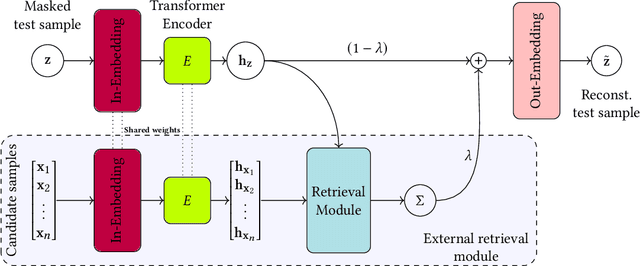

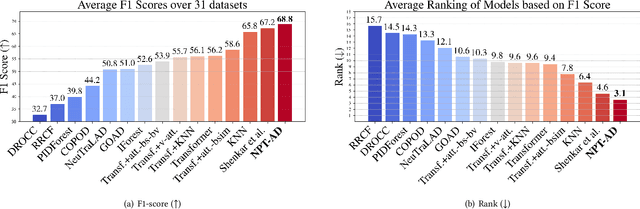

Deep learning for tabular data has garnered increasing attention in recent years, yet employing deep models for structured data remains challenging. While these models excel with unstructured data, their efficacy with structured data has been limited. Recent research has introduced retrieval-augmented models to address this gap, demonstrating promising results in supervised tasks such as classification and regression. In this work, we investigate using retrieval-augmented models for anomaly detection on tabular data. We propose a reconstruction-based approach in which a transformer model learns to reconstruct masked features of \textit{normal} samples. We test the effectiveness of KNN-based and attention-based modules to select relevant samples to help in the reconstruction process of the target sample. Our experiments on a benchmark of 31 tabular datasets reveal that augmenting this reconstruction-based anomaly detection (AD) method with non-parametric relationships via retrieval modules may significantly boost performance.
Comparative Evaluation of Anomaly Detection Methods for Fraud Detection in Online Credit Card Payments
Dec 21, 2023This study explores the application of anomaly detection (AD) methods in imbalanced learning tasks, focusing on fraud detection using real online credit card payment data. We assess the performance of several recent AD methods and compare their effectiveness against standard supervised learning methods. Offering evidence of distribution shift within our dataset, we analyze its impact on the tested models' performances. Our findings reveal that LightGBM exhibits significantly superior performance across all evaluated metrics but suffers more from distribution shifts than AD methods. Furthermore, our investigation reveals that LightGBM also captures the majority of frauds detected by AD methods. This observation challenges the potential benefits of ensemble methods to combine supervised, and AD approaches to enhance performance. In summary, this research provides practical insights into the utility of these techniques in real-world scenarios, showing LightGBM's superiority in fraud detection while highlighting challenges related to distribution shifts.
Benchmarking Robustness of Deep Reinforcement Learning approaches to Online Portfolio Management
Jun 19, 2023


Deep Reinforcement Learning approaches to Online Portfolio Selection have grown in popularity in recent years. The sensitive nature of training Reinforcement Learning agents implies a need for extensive efforts in market representation, behavior objectives, and training processes, which have often been lacking in previous works. We propose a training and evaluation process to assess the performance of classical DRL algorithms for portfolio management. We found that most Deep Reinforcement Learning algorithms were not robust, with strategies generalizing poorly and degrading quickly during backtesting.
Beyond Individual Input for Deep Anomaly Detection on Tabular Data
May 24, 2023Anomaly detection is crucial in various domains, such as finance, healthcare, and cybersecurity. In this paper, we propose a novel deep anomaly detection method for tabular data that leverages Non-Parametric Transformers (NPTs), a model initially proposed for supervised tasks, to capture both feature-feature and sample-sample dependencies. In a reconstruction-based framework, we train the NPT model to reconstruct masked features of normal samples. We use the model's ability to reconstruct the masked features during inference to generate an anomaly score. To the best of our knowledge, our proposed method is the first to combine both feature-feature and sample-sample dependencies for anomaly detection on tabular datasets. We evaluate our method on an extensive benchmark of tabular datasets and demonstrate that our approach outperforms existing state-of-the-art methods based on both the F1-Score and AUROC. Moreover, our work opens up new research directions for exploring the potential of NPTs for other tasks on tabular data.
TracInAD: Measuring Influence for Anomaly Detection
May 04, 2022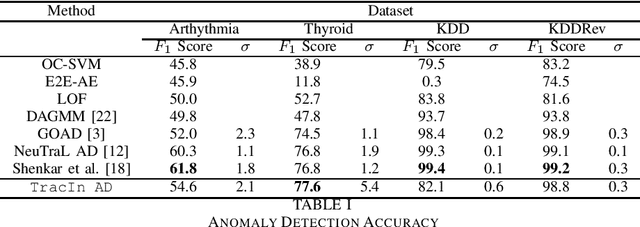
As with many other tasks, neural networks prove very effective for anomaly detection purposes. However, very few deep-learning models are suited for detecting anomalies on tabular datasets. This paper proposes a novel methodology to flag anomalies based on TracIn, an influence measure initially introduced for explicability purposes. The proposed methods can serve to augment any unsupervised deep anomaly detection method. We test our approach using Variational Autoencoders and show that the average influence of a subsample of training points on a test point can serve as a proxy for abnormality. Our model proves to be competitive in comparison with state-of-the-art approaches: it achieves comparable or better performance in terms of detection accuracy on medical and cyber-security tabular benchmark data.
Quantum Semantic Correlations in Hate and Non-Hate Speeches
Nov 08, 2018
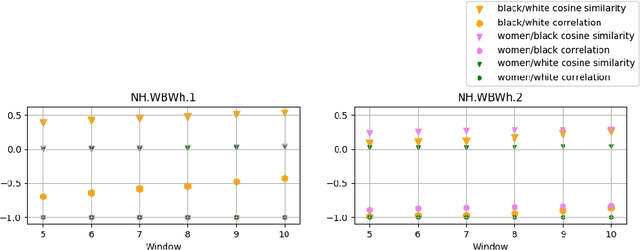


This paper aims to apply the notions of quantum geometry and correlation to the typification of semantic relations between couples of keywords in different documents. In particular we analysed texts classified as hate / non hate speeches, containing the keywords "women", "white", and "black". The paper compares this approach to cosine similarity, a classical methodology, to cast light on the notion of "similar meaning".
* In Proceedings CAPNS 2018, arXiv:1811.02701