 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthAttLyzer-V2: Unveiling Code Authorship Attribution using Enhanced Ensemble Learning Models & Generating Benchmark Dataset
Jun 28, 2024



Source Code Authorship Attribution (SCAA) is crucial for software classification because it provides insights into the origin and behavior of software. By accurately identifying the author or group behind a piece of code, experts can better understand the motivations and techniques of developers. In the cybersecurity era, this attribution helps trace the source of malicious software, identify patterns in the code that may indicate specific threat actors or groups, and ultimately enhance threat intelligence and mitigation strategies. This paper presents AuthAttLyzer-V2, a new source code feature extractor for SCAA, focusing on lexical, semantic, syntactic, and N-gram features. Our research explores author identification in C++ by examining 24,000 source code samples from 3,000 authors. Our methodology integrates Random Forest, Gradient Boosting, and XGBoost models, enhanced with SHAP for interpretability. The study demonstrates how ensemble models can effectively discern individual coding styles, offering insights into the unique attributes of code authorship. This approach is pivotal in understanding and interpreting complex patterns in authorship attribution, especially for malware classification.
RaCIL: Ray Tracing based Multi-UAV Obstacle Avoidance through Composite Imitation Learning
Jun 24, 2024In this study, we address the challenge of obstacle avoidance for Unmanned Aerial Vehicles (UAVs) through an innovative composite imitation learning approach that combines Proximal Policy Optimization (PPO) with Behavior Cloning (BC) and Generative Adversarial Imitation Learning (GAIL), enriched by the integration of ray-tracing techniques. Our research underscores the significant role of ray-tracing in enhancing obstacle detection and avoidance capabilities. Moreover, we demonstrate the effectiveness of incorporating GAIL in coordinating the flight paths of two UAVs, showcasing improved collision avoidance capabilities. Extending our methodology, we apply our combined PPO, BC, GAIL, and ray-tracing framework to scenarios involving four UAVs, illustrating its scalability and adaptability to more complex scenarios. The findings indicate that our approach not only improves the reliability of basic PPO based obstacle avoidance but also paves the way for advanced autonomous UAV operations in crowded or dynamic environments.
Sim-to-Real Deep Reinforcement Learning based Obstacle Avoidance for UAVs under Measurement Uncertainty
Mar 13, 2023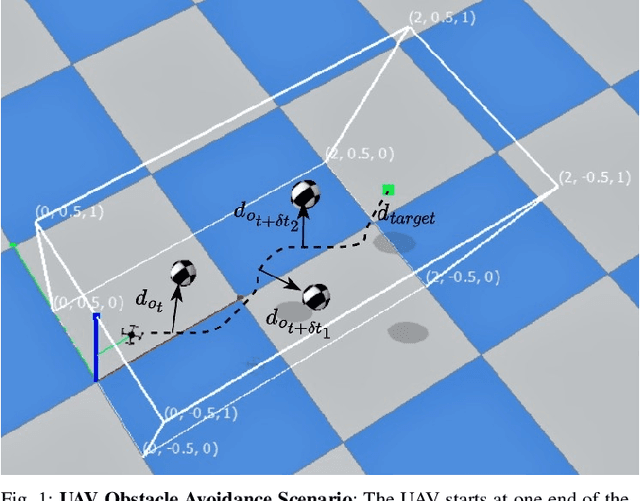
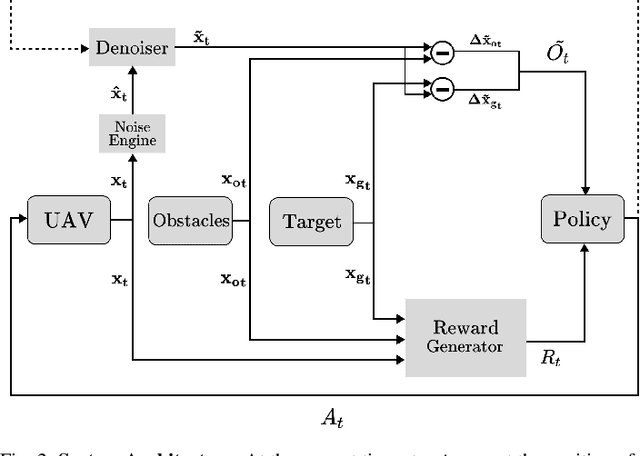
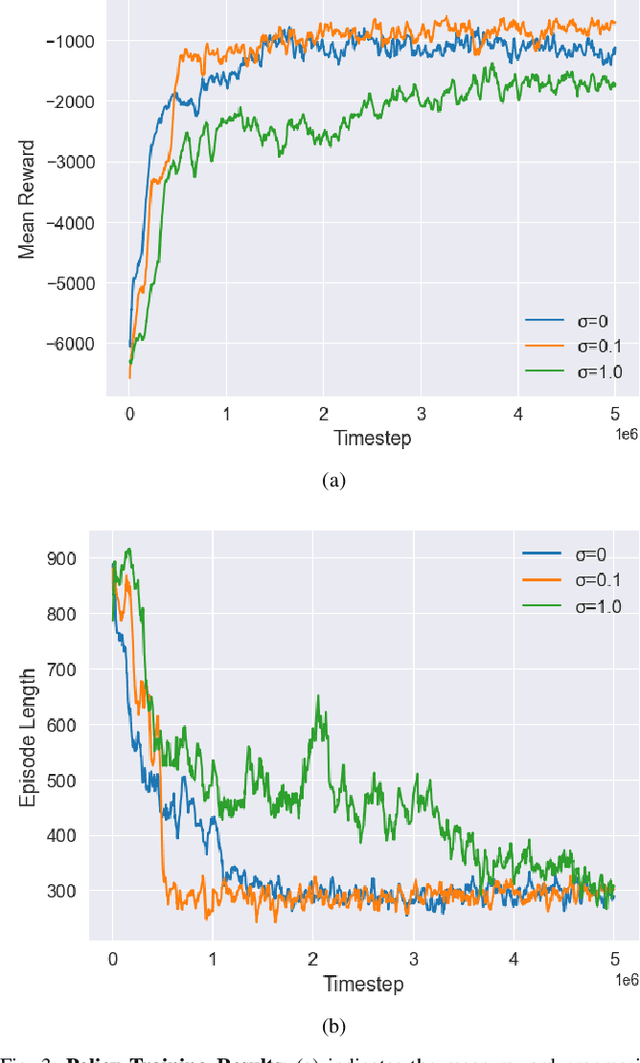
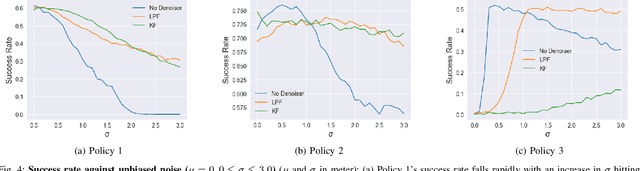
Deep Reinforcement Learning is quickly becoming a popular method for training autonomous Unmanned Aerial Vehicles (UAVs). Our work analyzes the effects of measurement uncertainty on the performance of Deep Reinforcement Learning (DRL) based waypoint navigation and obstacle avoidance for UAVs. Measurement uncertainty originates from noise in the sensors used for localization and detecting obstacles. Measurement uncertainty/noise is considered to follow a Gaussian probability distribution with unknown non-zero mean and variance. We evaluate the performance of a DRL agent trained using the Proximal Policy Optimization (PPO) algorithm in an environment with continuous state and action spaces. The environment is randomized with different numbers of obstacles for each simulation episode in the presence of varying degrees of noise, to capture the effects of realistic sensor measurements. Denoising techniques like the low pass filter and Kalman filter improve performance in the presence of unbiased noise. Moreover, we show that artificially injecting noise into the measurements during evaluation actually improves performance in certain scenarios. Extensive training and testing of the DRL agent under various UAV navigation scenarios are performed in the PyBullet physics simulator. To evaluate the practical validity of our method, we port the policy trained in simulation onto a real UAV without any further modifications and verify the results in a real-world environment.