 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification Via the Posterior Predictive Variance
Mar 20, 2026We use the law of total variance to generate multiple expansions for the posterior predictive variance. These expansions are sums of terms involving conditional expectations and conditional variances and provide a quantification of the sources of predictive uncertainty. Since the posterior predictive variance is fixed given the model, it represents a constant quantity that is conserved over these expansions. The terms in the expansions can be assessed in absolute or relative sense to understand the main contributors to the length of prediction intervals. We quantify the term-wise uncertainty across expansions varying in the number of terms and the order of conditionates. In particular, given that a specific term in one expansion is small or zero, we identify the other terms in other expansions that must also be small or zero. We illustrate this approach to predictive model assessment in several well-known models.
Changepoint Detection As Model Selection: A General Framework
Jan 30, 2026This dissertation presents a general framework for changepoint detection based on L0 model selection. The core method, Iteratively Reweighted Fused Lasso (IRFL), improves upon the generalized lasso by adaptively reweighting penalties to enhance support recovery and minimize criteria such as the Bayesian Information Criterion (BIC). The approach allows for flexible modeling of seasonal patterns, linear and quadratic trends, and autoregressive dependence in the presence of changepoints. Simulation studies demonstrate that IRFL achieves accurate changepoint detection across a wide range of challenging scenarios, including those involving nuisance factors such as trends, seasonal patterns, and serially correlated errors. The framework is further extended to image data, where it enables edge-preserving denoising and segmentation, with applications spanning medical imaging and high-throughput plant phenotyping. Applications to real-world data demonstrate IRFL's utility. In particular, analysis of the Mauna Loa CO2 time series reveals changepoints that align with volcanic eruptions and ENSO events, yielding a more accurate trend decomposition than ordinary least squares. Overall, IRFL provides a robust, extensible tool for detecting structural change in complex data.
Point Prediction for Streaming Data
Aug 02, 2024



We present two new approaches for point prediction with streaming data. One is based on the Count-Min sketch (CMS) and the other is based on Gaussian process priors with a random bias. These methods are intended for the most general predictive problems where no true model can be usefully formulated for the data stream. In statistical contexts, this is often called the $\mathcal{M}$-open problem class. Under the assumption that the data consists of i.i.d samples from a fixed distribution function $F$, we show that the CMS-based estimates of the distribution function are consistent. We compare our new methods with two established predictors in terms of cumulative $L^1$ error. One is based on the Shtarkov solution (often called the normalized maximum likelihood) in the normal experts setting and the other is based on Dirichlet process priors. These comparisons are for two cases. The first is one-pass meaning that the updating of the predictors is done using the fact that the CMS is a sketch. For predictors that are not one-pass, we use streaming $K$-means to give a representative subset of fixed size that can be updated as data accumulate. Preliminary computational work suggests that the one-pass median version of the CMS method is rarely outperformed by the other methods for sufficiently complex data. We also find that predictors based on Gaussian process priors with random biases perform well. The Shtarkov predictors we use here did not perform as well probably because we were only using the simplest example. The other predictors seemed to perform well mainly when the data did not look like they came from an M-open data generator.
Clustering categorical data via ensembling dissimilarity matrices
Jun 26, 2015
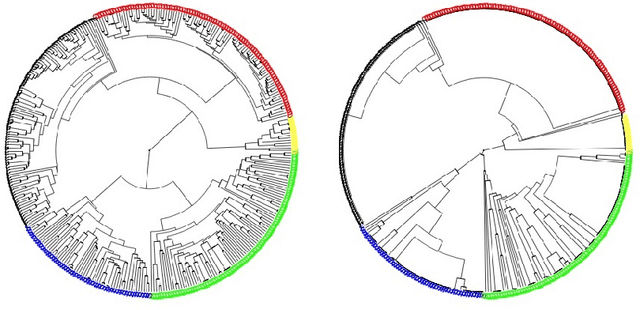

We present a technique for clustering categorical data by generating many dissimilarity matrices and averaging over them. We begin by demonstrating our technique on low dimensional categorical data and comparing it to several other techniques that have been proposed. Then we give conditions under which our method should yield good results in general. Our method extends to high dimensional categorical data of equal lengths by ensembling over many choices of explanatory variables. In this context we compare our method with two other methods. Finally, we extend our method to high dimensional categorical data vectors of unequal length by using alignment techniques to equalize the lengths. We give examples to show that our method continues to provide good results, in particular, better in the context of genome sequences than clusterings suggested by phylogenetic trees.
A General Hybrid Clustering Technique
Mar 05, 2015



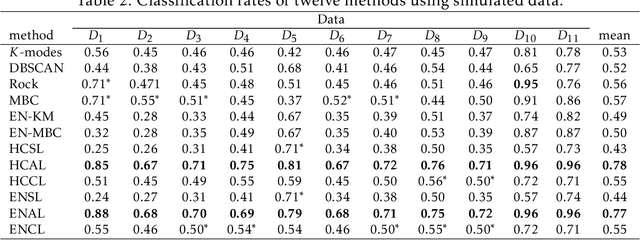
Here, we propose a clustering technique for general clustering problems including those that have non-convex clusters. For a given desired number of clusters $K$, we use three stages to find a clustering. The first stage uses a hybrid clustering technique to produce a series of clusterings of various sizes (randomly selected). They key steps are to find a $K$-means clustering using $K_\ell$ clusters where $K_\ell \gg K$ and then joins these small clusters by using single linkage clustering. The second stage stabilizes the result of stage one by reclustering via the `membership matrix' under Hamming distance to generate a dendrogram. The third stage is to cut the dendrogram to get $K^*$ clusters where $K^* \geq K$ and then prune back to $K$ to give a final clustering. A variant on our technique also gives a reasonable estimate for $K_T$, the true number of clusters. We provide a series of arguments to justify the steps in the stages of our methods and we provide numerous examples involving real and simulated data to compare our technique with other related techniques.