 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtensive Error Analysis and a Learning-Based Evaluation of Medical Entity Recognition Systems to Approximate User Experience
Jun 09, 2020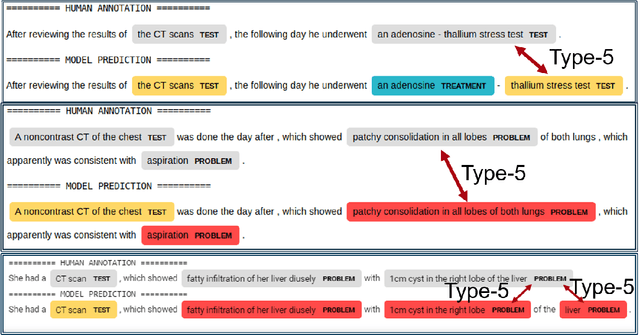



When comparing entities extracted by a medical entity recognition system with gold standard annotations over a test set, two types of mismatches might occur, label mismatch or span mismatch. Here we focus on span mismatch and show that its severity can vary from a serious error to a fully acceptable entity extraction due to the subjectivity of span annotations. For a domain-specific BERT-based NER system, we showed that 25% of the errors have the same labels and overlapping span with gold standard entities. We collected expert judgement which shows more than 90% of these mismatches are accepted or partially accepted by the user. Using the training set of the NER system, we built a fast and lightweight entity classifier to approximate the user experience of such mismatches through accepting or rejecting them. The decisions made by this classifier are used to calculate a learning-based F-score which is shown to be a better approximation of a forgiving user's experience than the relaxed F-score. We demonstrated the results of applying the proposed evaluation metric for a variety of deep learning medical entity recognition models trained with two datasets.
Extracting UMLS Concepts from Medical Text Using General and Domain-Specific Deep Learning Models
Oct 03, 2019



Entity recognition is a critical first step to a number of clinical NLP applications, such as entity linking and relation extraction. We present the first attempt to apply state-of-the-art entity recognition approaches on a newly released dataset, MedMentions. This dataset contains over 4000 biomedical abstracts, annotated for UMLS semantic types. In comparison to existing datasets, MedMentions contains a far greater number of entity types, and thus represents a more challenging but realistic scenario in a real-world setting. We explore a number of relevant dimensions, including the use of contextual versus non-contextual word embeddings, general versus domain-specific unsupervised pre-training, and different deep learning architectures. We contrast our results against the well-known i2b2 2010 entity recognition dataset, and propose a new method to combine general and domain-specific information. While producing a state-of-the-art result for the i2b2 2010 task (F1 = 0.90), our results on MedMentions are significantly lower (F1 = 0.63), suggesting there is still plenty of opportunity for improvement on this new data.