 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Monocular Depth Estimation of Untextured Indoor Rotated Scenes
Jun 25, 2021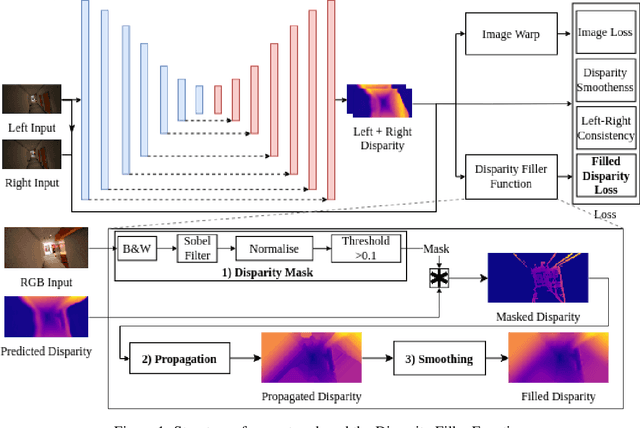


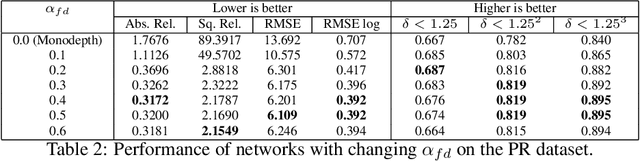
Self-supervised deep learning methods have leveraged stereo images for training monocular depth estimation. Although these methods show strong results on outdoor datasets such as KITTI, they do not match performance of supervised methods on indoor environments with camera rotation. Indoor, rotated scenes are common for less constrained applications and pose problems for two reasons: abundance of low texture regions and increased complexity of depth cues for images under rotation. In an effort to extend self-supervised learning to more generalised environments we propose two additions. First, we propose a novel Filled Disparity Loss term that corrects for ambiguity of image reconstruction error loss in textureless regions. Specifically, we interpolate disparity in untextured regions, using the estimated disparity from surrounding textured areas, and use L1 loss to correct the original estimation. Our experiments show that depth estimation is substantially improved on low-texture scenes, without any loss on textured scenes, when compared to Monodepth by Godard et al. Secondly, we show that training with an application's representative rotations, in both pitch and roll, is sufficient to significantly improve performance over the entire range of expected rotation. We demonstrate that depth estimation is successfully generalised as performance is not lost when evaluated on test sets with no camera rotation. Together these developments enable a broader use of self-supervised learning of monocular depth estimation for complex environments.