 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexLiDAR: Automated Text Understanding for Panoramic LiDAR Data
Feb 05, 2025



Efforts to connect LiDAR data with text, such as LidarCLIP, have primarily focused on embedding 3D point clouds into CLIP text-image space. However, these approaches rely on 3D point clouds, which present challenges in encoding efficiency and neural network processing. With the advent of advanced LiDAR sensors like Ouster OS1, which, in addition to 3D point clouds, produce fixed resolution depth, signal, and ambient panoramic 2D images, new opportunities emerge for LiDAR based tasks. In this work, we propose an alternative approach to connect LiDAR data with text by leveraging 2D imagery generated by the OS1 sensor instead of 3D point clouds. Using the Florence 2 large model in a zero-shot setting, we perform image captioning and object detection. Our experiments demonstrate that Florence 2 generates more informative captions and achieves superior performance in object detection tasks compared to existing methods like CLIP. By combining advanced LiDAR sensor data with a large pre-trained model, our approach provides a robust and accurate solution for challenging detection scenarios, including real-time applications requiring high accuracy and robustness.
NextStop: An Improved Tracker For Panoptic LIDAR Segmentation Data
Jan 08, 2025



4D panoptic LiDAR segmentation is essential for scene understanding in autonomous driving and robotics ,combining semantic and instance segmentation with temporal consistency.Current methods, like 4D-PLS and 4D-STOP, use a tracking-by-detection methodology, employing deep learning networks to perform semantic and instance segmentation on each frame. To maintain temporal consistency, large-size instances detected in the current frame are compared and associated with instances within a temporal window that includes the current and preceding frames. However, their reliance on short-term instance detection, lack of motion estimation, and exclusion of small-sized instances lead to frequent identity switches and reduced tracking performance. We address these issues with the NextStop1 tracker, which integrates Kalman filter-based motion estimation, data association, and lifespan management, along with a tracklet state concept to improve prioritization. Evaluated using the LiDAR Segmentation and Tracking Quality (LSTQ) metric on the SemanticKITTI validation set, NextStop demonstrated enhanced tracking performance, particularly for small-sized objects like people and bicyclists, with fewer ID switches, earlier tracking initiation, and improved reliability in complex environments. The source code is available at https://github.com/AIROTAU/NextStopTracker
Real-Time 3D Object Detection Using InnovizOne LiDAR and Low-Power Hailo-8 AI Accelerator
Dec 07, 2024
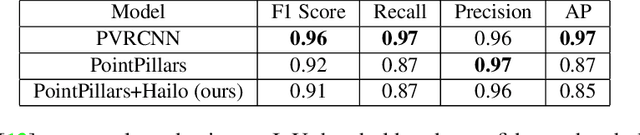


Object detection is a significant field in autonomous driving. Popular sensors for this task include cameras and LiDAR sensors. LiDAR sensors offer several advantages, such as insensitivity to light changes, like in a dark setting and the ability to provide 3D information in the form of point clouds, which include the ranges of objects. However, 3D detection methods, such as PointPillars, typically require high-power hardware. Additionally, most common spinning LiDARs are sparse and may not achieve the desired quality of object detection in front of the car. In this paper, we present the feasibility of performing real-time 3D object detection of cars using 3D point clouds from a LiDAR sensor, processed and deployed on a low-power Hailo-8 AI accelerator. The LiDAR sensor used in this study is the InnovizOne sensor, which captures objects in higher quality compared to spinning LiDAR techniques, especially for distant objects. We successfully achieved real-time inference at a rate of approximately 5Hz with a high accuracy of 0.91% F1 score, with only -0.2% degradation compared to running the same model on an NVIDIA GeForce RTX 2080 Ti. This work demonstrates that effective real-time 3D object detection can be achieved on low-cost, low-power hardware, representing a significant step towards more accessible autonomous driving technologies. The source code and the pre-trained models are available at https://github.com/AIROTAU/ PointPillarsHailoInnoviz/tree/main
CLRmatchNet: Enhancing Curved Lane Detection with Deep Matching Process
Sep 26, 2023Lane detection plays a crucial role in autonomous driving by providing vital data to ensure safe navigation. Modern algorithms rely on anchor-based detectors, which are then followed by a label assignment process to categorize training detections as positive or negative instances based on learned geometric attributes. The current methods, however, have limitations and might not be optimal since they rely on predefined classical cost functions that are based on a low-dimensional model. Our research introduces MatchNet, a deep learning sub-module-based approach aimed at enhancing the label assignment process. Integrated into a state-of-the-art lane detection network like the Cross Layer Refinement Network for Lane Detection (CLRNet), MatchNet replaces the conventional label assignment process with a sub-module network. This integration results in significant improvements in scenarios involving curved lanes, with remarkable improvement across all backbones of +2.8% for ResNet34, +2.3% for ResNet101, and +2.96% for DLA34. In addition, it maintains or even improves comparable results in other sections. Our method boosts the confidence level in lane detection, allowing an increase in the confidence threshold. The code will be available soon: https://github.com/sapirkontente/CLRmatchNet.git
Strong-TransCenter: Improved Multi-Object Tracking based on Transformers with Dense Representations
Oct 24, 2022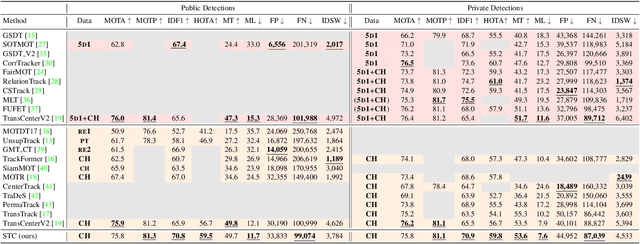
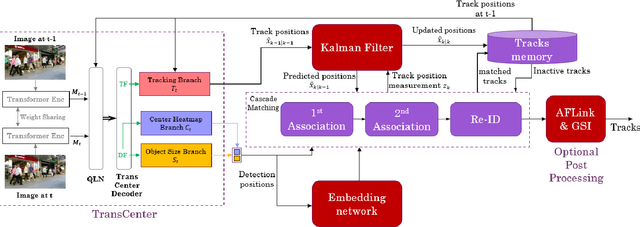
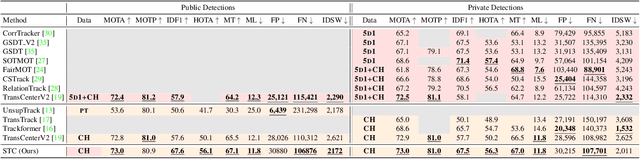
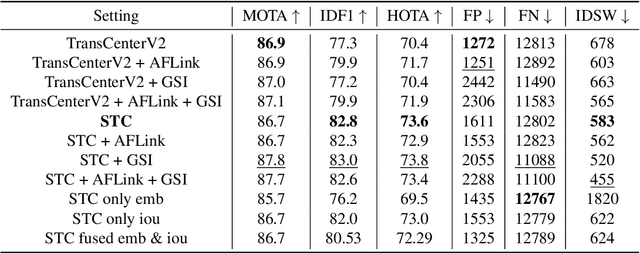
Transformer networks have been a focus of research in many fields in recent years, being able to surpass the state-of-the-art performance in different computer vision tasks. A few attempts have been made to apply this method to the task of Multiple Object Tracking (MOT), among those the state-of-the-art was TransCenter, a transformer-based MOT architecture with dense object queries for accurately tracking all the objects while keeping reasonable runtime. TransCenter is the first center-based transformer framework for MOT, and is also among the first to show the benefits of using transformer-based architectures for MOT. In this paper we show an improvement to this tracker using post processing mechanism based in the Track-by-Detection paradigm: motion model estimation using Kalman filter and target Re-identification using an embedding network. Our new tracker shows significant improvements in the IDF1 and HOTA metrics and comparable results on the MOTA metric (70.9%, 59.8% and 75.8% respectively) on the MOTChallenge MOT17 test dataset and improvement on all 3 metrics (67.5%, 56.3% and 73.0%) on the MOT20 test dataset. Our tracker is currently ranked first among transformer-based trackers in these datasets. The code is publicly available at: https://github.com/amitgalor18/STC_Tracker
BoT-SORT: Robust Associations Multi-Pedestrian Tracking
Jul 07, 2022

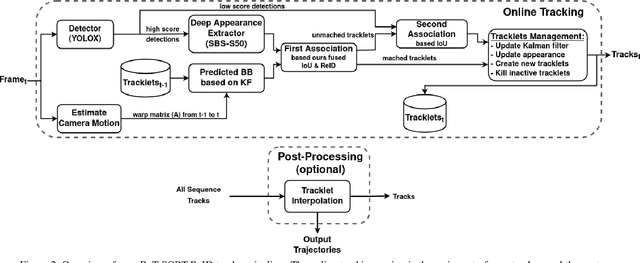
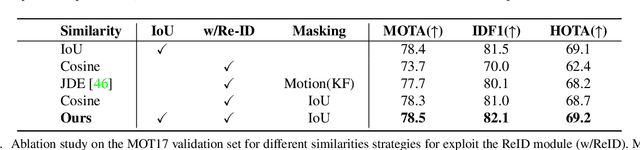
The goal of multi-object tracking (MOT) is detecting and tracking all the objects in a scene, while keeping a unique identifier for each object. In this paper, we present a new robust state-of-the-art tracker, which can combine the advantages of motion and appearance information, along with camera-motion compensation, and a more accurate Kalman filter state vector. Our new trackers BoT-SORT, and BoT-SORT-ReID rank first in the datasets of MOTChallenge [29, 11] on both MOT17 and MOT20 test sets, in terms of all the main MOT metrics: MOTA, IDF1, and HOTA. For MOT17: 80.5 MOTA, 80.2 IDF1, and 65.0 HOTA are achieved. The source code and the pre-trained models are available at https://github.com/NirAharon/BOT-SORT
Insights on Evaluation of Camera Re-localization Using Relative Pose Regression
Sep 23, 2020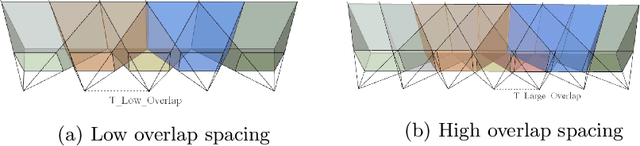
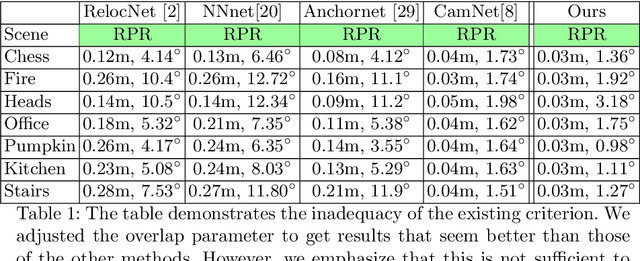
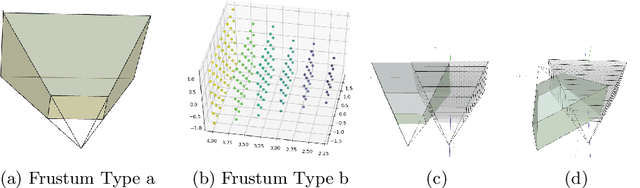
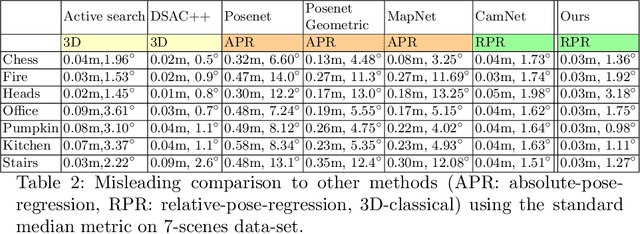
We consider the problem of relative pose regression in visual relocalization. Recently, several promising approaches have emerged in this area. We claim that even though they demonstrate on the same datasets using the same split to train and test, a faithful comparison between them was not available since on currently used evaluation metric, some approaches might perform favorably, while in reality performing worse. We reveal a tradeoff between accuracy and the 3D volume of the regressed subspace. We believe that unlike other relocalization approaches, in the case of relative pose regression, the regressed subspace 3D volume is less dependent on the scene and more affect by the method used to score the overlap, which determined how closely sampled viewpoints are. We propose three new metrics to remedy the issue mentioned above. The proposed metrics incorporate statistics about the regression subspace volume. We also propose a new pose regression network that serves as a new baseline for this task. We compare the performance of our trained model on Microsoft 7-Scenes and Cambridge Landmarks datasets both with the standard metrics and the newly proposed metrics and adjust the overlap score to reveal the tradeoff between the subspace and performance. The results show that the proposed metrics are more robust to different overlap threshold than the conventional approaches. Finally, we show that our network generalizes well, specifically, training on a single scene leads to little loss of performance on the other scenes.