 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgecovLLM: Large Language Models for COVID-19 Biomedical Literature
Jun 08, 2023



The COVID-19 pandemic led to 1.1 million deaths in the United States, despite the explosion of coronavirus research. These new findings are slow to translate to clinical interventions, leading to poorer patient outcomes and unnecessary deaths. One reason is that clinicians, overwhelmed by patients, struggle to keep pace with the rate of new coronavirus literature. A potential solution is developing a tool for evaluating coronavirus literature using large language models (LLMs) -- neural networks that are deployed for natural language processing. LLMs can be used to summarize and extract user-specified information. The greater availability and advancement of LLMs and pre-processed coronavirus literature databases provide the opportunity to assist clinicians in evaluating coronavirus literature through a coronavirus literature specific LLM (covLLM), a tool that directly takes an inputted research article and a user query to return an answer. Using the COVID-19 Open Research Dataset (CORD-19), we produced two datasets: (1) synCovid, which uses a combination of handwritten prompts and synthetic prompts generated using OpenAI, and (2) real abstracts, which contains abstract and title pairs. covLLM was trained with LLaMA 7B as a baseline model to produce three models trained on (1) the Alpaca and synCovid datasets, (2) the synCovid dataset, and (3) the synCovid and real abstract datasets. These models were evaluated by two human evaluators and ChatGPT. Results demonstrate that training covLLM on the synCovid and abstract pairs datasets performs competitively with ChatGPT and outperforms covLLM trained primarily using the Alpaca dataset.
Forward Thinking: Building and Training Neural Networks One Layer at a Time
Jun 08, 2017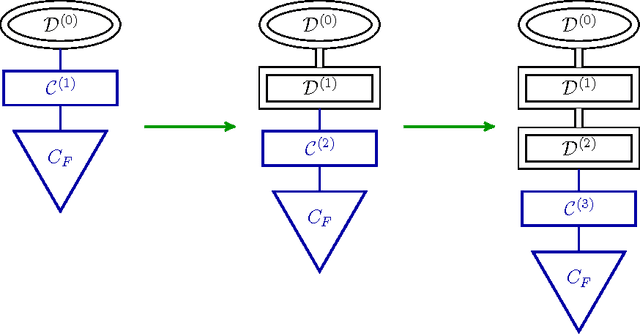
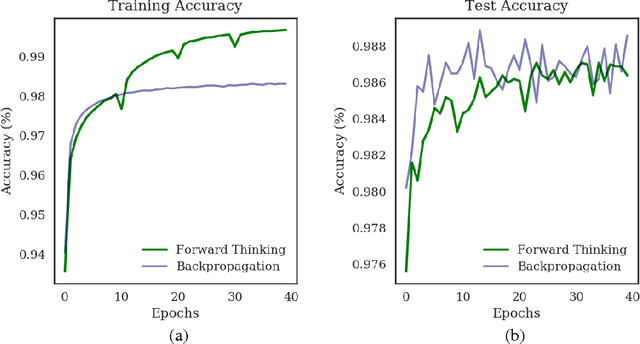
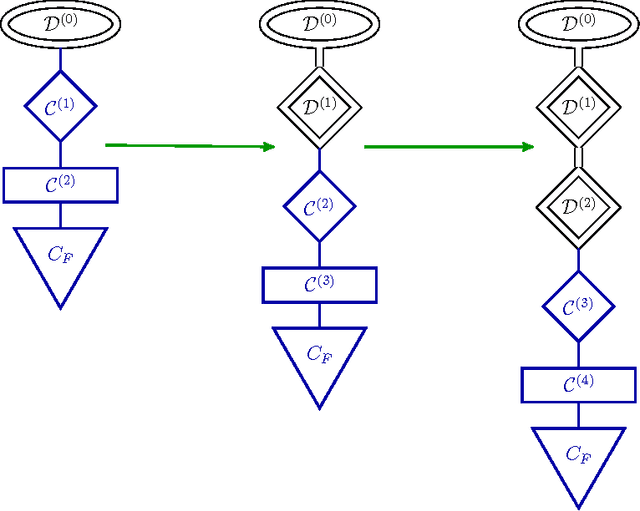
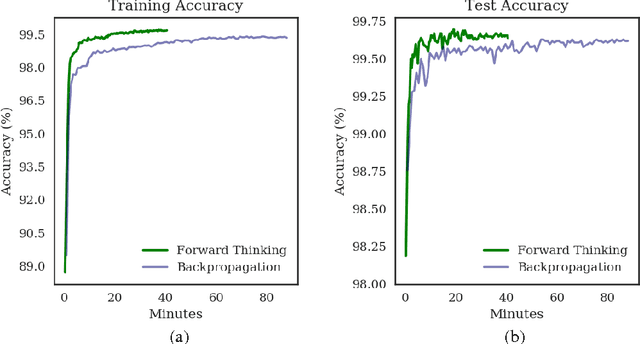
We present a general framework for training deep neural networks without backpropagation. This substantially decreases training time and also allows for construction of deep networks with many sorts of learners, including networks whose layers are defined by functions that are not easily differentiated, like decision trees. The main idea is that layers can be trained one at a time, and once they are trained, the input data are mapped forward through the layer to create a new learning problem. The process is repeated, transforming the data through multiple layers, one at a time, rendering a new data set, which is expected to be better behaved, and on which a final output layer can achieve good performance. We call this forward thinking and demonstrate a proof of concept by achieving state-of-the-art accuracy on the MNIST dataset for convolutional neural networks. We also provide a general mathematical formulation of forward thinking that allows for other types of deep learning problems to be considered.