 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Adversarial Training for Unsupervised Domain Adaptation
Jul 17, 2024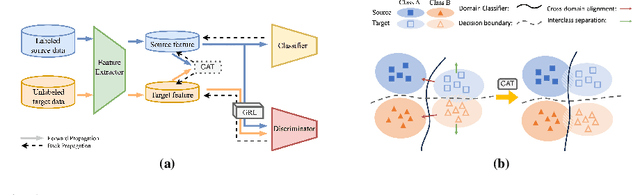
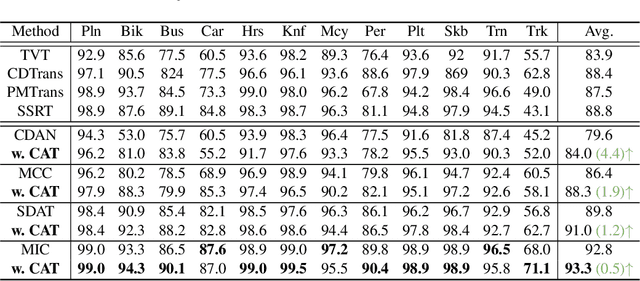
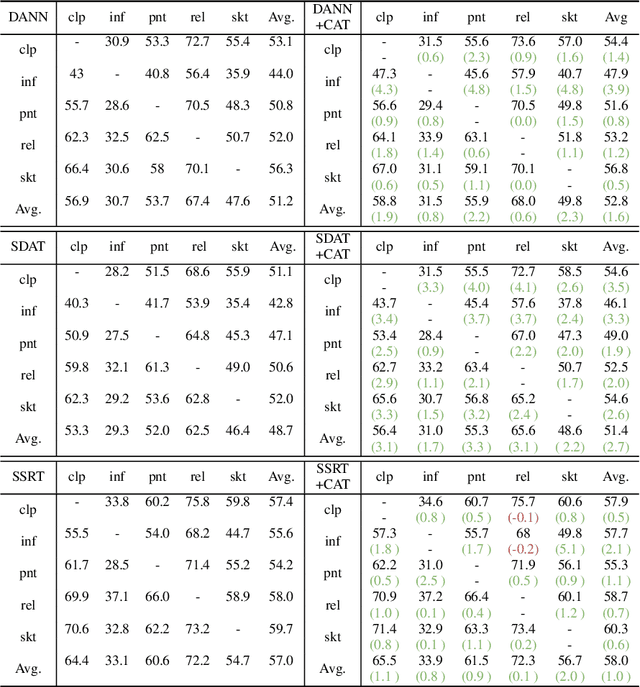
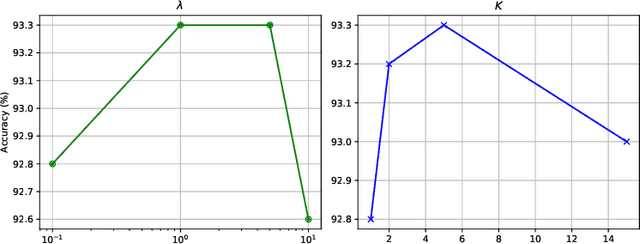
Domain adversarial training has shown its effective capability for finding domain invariant feature representations and been successfully adopted for various domain adaptation tasks. However, recent advances of large models (e.g., vision transformers) and emerging of complex adaptation scenarios (e.g., DomainNet) make adversarial training being easily biased towards source domain and hardly adapted to target domain. The reason is twofold: relying on large amount of labelled data from source domain for large model training and lacking of labelled data from target domain for fine-tuning. Existing approaches widely focused on either enhancing discriminator or improving the training stability for the backbone networks. Due to unbalanced competition between the feature extractor and the discriminator during the adversarial training, existing solutions fail to function well on complex datasets. To address this issue, we proposed a novel contrastive adversarial training (CAT) approach that leverages the labeled source domain samples to reinforce and regulate the feature generation for target domain. Typically, the regulation forces the target feature distribution being similar to the source feature distribution. CAT addressed three major challenges in adversarial learning: 1) ensure the feature distributions from two domains as indistinguishable as possible for the discriminator, resulting in a more robust domain-invariant feature generation; 2) encourage target samples moving closer to the source in the feature space, reducing the requirement for generalizing classifier trained on the labeled source domain to unlabeled target domain; 3) avoid directly aligning unpaired source and target samples within mini-batch. CAT can be easily plugged into existing models and exhibits significant performance improvements.
On Detecting Data Pollution Attacks On Recommender Systems Using Sequential GANs
Dec 04, 2020
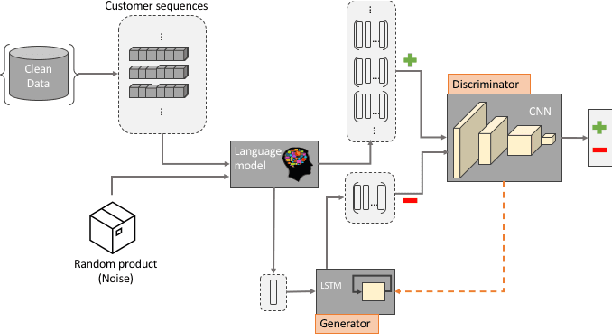
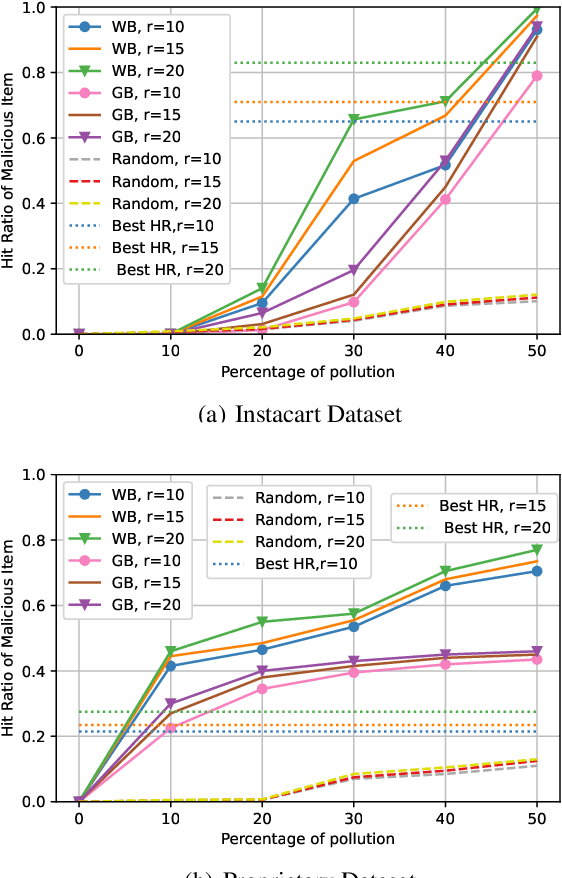

Recommender systems are an essential part of any e-commerce platform. Recommendations are typically generated by aggregating large amounts of user data. A malicious actor may be motivated to sway the output of such recommender systems by injecting malicious datapoints to leverage the system for financial gain. In this work, we propose a semi-supervised attack detection algorithm to identify the malicious datapoints. We do this by leveraging a portion of the dataset that has a lower chance of being polluted to learn the distribution of genuine datapoints. Our proposed approach modifies the Generative Adversarial Network architecture to take into account the contextual information from user activity. This allows the model to distinguish legitimate datapoints from the injected ones.