 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo deep neural networks utilize the weight space efficiently?
Jan 26, 2024Deep learning models like Transformers and Convolutional Neural Networks (CNNs) have revolutionized various domains, but their parameter-intensive nature hampers deployment in resource-constrained settings. In this paper, we introduce a novel concept utilizes column space and row space of weight matrices, which allows for a substantial reduction in model parameters without compromising performance. Leveraging this paradigm, we achieve parameter-efficient deep learning models.. Our approach applies to both Bottleneck and Attention layers, effectively halving the parameters while incurring only minor performance degradation. Extensive experiments conducted on the ImageNet dataset with ViT and ResNet50 demonstrate the effectiveness of our method, showcasing competitive performance when compared to traditional models. This approach not only addresses the pressing demand for parameter efficient deep learning solutions but also holds great promise for practical deployment in real-world scenarios.
Vehicle Detection and Classification without Residual Calculation: Accelerating HEVC Image Decoding with Random Perturbation Injection
May 14, 2023



In the field of video analytics, particularly traffic surveillance, there is a growing need for efficient and effective methods for processing and understanding video data. Traditional full video decoding techniques can be computationally intensive and time-consuming, leading researchers to explore alternative approaches in the compressed domain. This study introduces a novel random perturbation-based compressed domain method for reconstructing images from High Efficiency Video Coding (HEVC) bitstreams, specifically designed for traffic surveillance applications. To the best of our knowledge, our method is the first to propose substituting random perturbations for residual values, creating a condensed representation of the original image while retaining information relevant to video understanding tasks, particularly focusing on vehicle detection and classification as key use cases. By not using residual data, our proposed method significantly reduces the data needed in the image reconstruction process, allowing for more efficient storage and transmission of information. This is particularly important when considering the vast amount of video data involved in surveillance applications. Applied to the public BIT-Vehicle dataset, we demonstrate a significant increase in the reconstruction speed compared to the traditional full decoding approach, with our proposed method being approximately 56% faster than the pixel domain method. Additionally, we achieve a detection accuracy of 99.9%, on par with the pixel domain method, and a classification accuracy of 96.84%, only 0.98% lower than the pixel domain method. Furthermore, we showcase the significant reduction in data size, leading to more efficient storage and transmission. Our research establishes the potential of compressed domain methods in traffic surveillance applications, where speed and data size are critical factors.
Focus-and-Detect: A Small Object Detection Framework for Aerial Images
Mar 24, 2022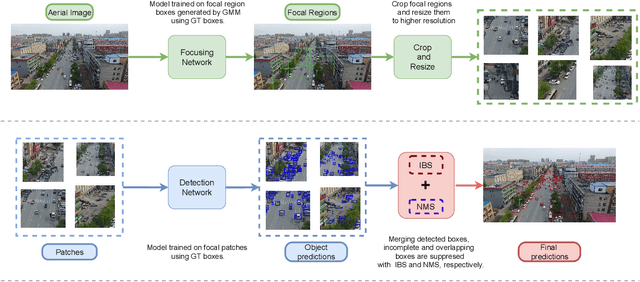

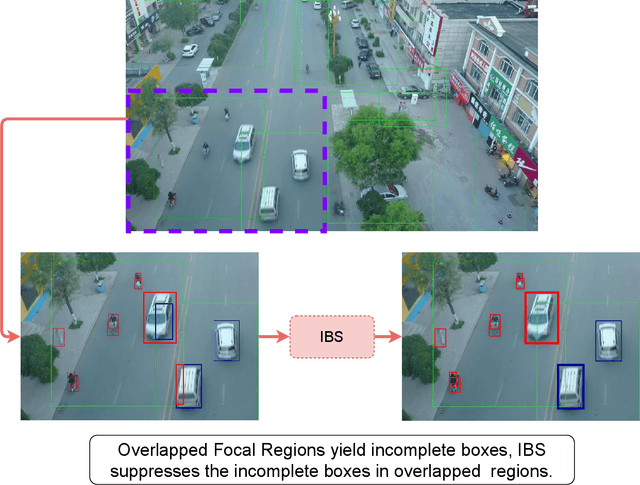

Despite recent advances, object detection in aerial images is still a challenging task. Specific problems in aerial images makes the detection problem harder, such as small objects, densely packed objects, objects in different sizes and with different orientations. To address small object detection problem, we propose a two-stage object detection framework called "Focus-and-Detect". The first stage which consists of an object detector network supervised by a Gaussian Mixture Model, generates clusters of objects constituting the focused regions. The second stage, which is also an object detector network, predicts objects within the focal regions. Incomplete Box Suppression (IBS) method is also proposed to overcome the truncation effect of region search approach. Results indicate that the proposed two-stage framework achieves an AP score of 42.06 on VisDrone validation dataset, surpassing all other state-of-the-art small object detection methods reported in the literature, to the best of authors' knowledge.
* 12 pages, 6 figures
Representation Learning using Graph Autoencoders with Residual Connections
May 03, 2021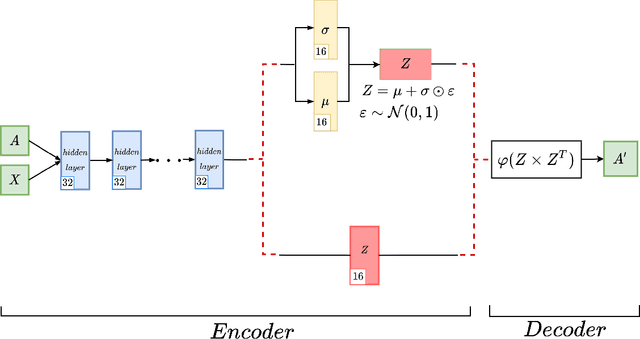
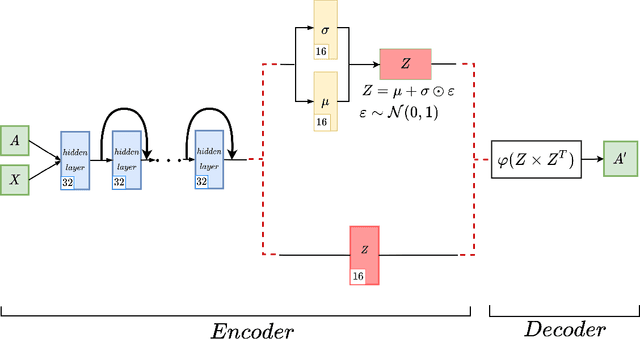
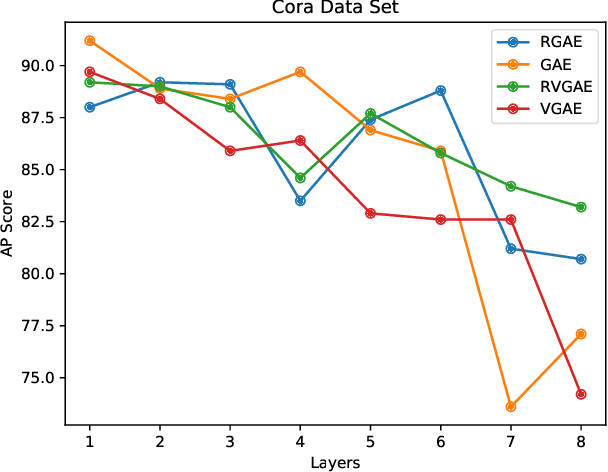
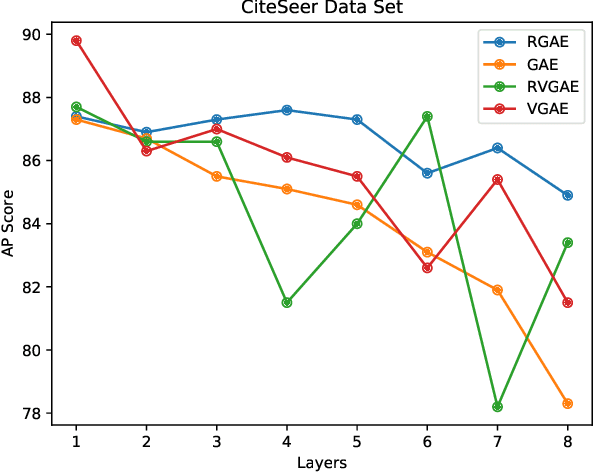
Graph autoencoders are very efficient at embedding graph-based complex data sets. However, most of the autoencoders have shallow depths and their efficiency tends to decrease with the increase of layer depth. In this paper, we study the effect of adding residual connections to shallow and deep graph variational and vanilla autoencoders. We show that residual connections improve the accuracy of the deep graph-based autoencoders. Furthermore, we propose Res-VGAE, a graph variational autoencoder with different residual connections. Our experiments show that our model achieves superior results when compared with other autoencoder-based models for the link prediction task.